
本研究针对现有临床实践指南评价方法和工具的不足,研发针对临床实践指南科学性(Scientificity)、透明性(Transparency)和适用性(Applicability)的评级(Rankings)工具,缩写为STAR,并对其信效度进行验证和对易用性进行评估。成立包含指南方法学家、统计学家、期刊编辑、医务人员等多学科的专家工作组,基于概况性评价、德尔菲法和层次分析法确定评级领域条目和相应分值,通过共识会议确定工具清单,并对工具进行信度、效度和易用性验证。最终形成11个领域39个条目和相应分值的综合性评价工具。工具内在信度分析显示各领域平均Cronbach′s α系数值0.646;方法学评级人员和临床评级人员之间的信度Cohen′s kappa系数分别为0.783和0.618;条目整体内容效度指数0.905;效标效度分析决定系数(R2)为0.76;条目的易用性平均得分4.6,评价1部指南中位用时20 min。STAR具有良好的信效度和评级效率,可针对中国指南的科学性、透明性和适用性进行综合评级。


版权归中华医学会所有。
未经授权,不得转载、摘编本刊文章,不得使用本刊的版式设计。
除非特别声明,本刊刊出的所有文章不代表中华医学会和本刊编委会的观点。
临床实践指南(以下简称“指南”)是指导医务人员进行临床实践的重要工具[1]。高质量指南可规范诊疗行为,改善医疗质量,节约卫生成本[1, 2]。过去30年,中国发表的指南数量已超过1 000篇,近3年每年超过200篇[3, 4, 5]。
指南研究者采用指南研究与评价工具(Appraisal of Guidelines for Research and Evaluation,AGREE)[6]和卫生保健实践指南的报告条目(Reporting Items for Practice Guidelines in Healthcare,RIGHT)[7]等从指南的不同维度对中国指南进行了评价[8, 9, 10, 11, 12],然而,若要综合反映指南的质量和实施效果,现有的评价工具存在以下局限性:第一,未纳入某些影响指南质量的关键因素,例如指南的应用性[13]、透明性[14]和前瞻性注册[15]等;第二,未经过信度和效度验证或验证的范围和程度不足[16, 17, 18, 19];第三,工具主要用于评估指南方法学、报告或实施等单个维度;第四,若需多维度评价,则要采用多个工具,并投入大量人力和时间[20];第五,难以对合并的评价结果进行解读。
为解决上述问题和提升中国指南质量,在前期工作的基础上[20, 21, 22],笔者组建了针对指南科学性(Scientificity)、透明性(Transparency)和适用性(Applicability)评级(Rankings)工作组,以下简称STAR工作组,旨在研发更全面的指南评级工具。
STAR工具主要的使用人群为指南的评价和评级人员,指南制订者、实施者和研究者也可利用该工具协助完成各自的工作。STAR工具的研发主要参照相关的方法学[23],主要包括:(1)概况性评价(Scoping review);(2)德尔菲调查;(3)层次分析法;(4)共识会议;(5)信度、效度和易用性测试。主要步骤路线见图1。
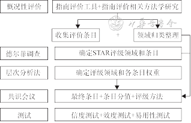
STAR项目工作组的建立,充分考虑地域的代表性和专业的代表性,成员来自全国东、南、中、西、北五大区域和不同专业背景的多学科专家(指南方法学家、统计学家、期刊编辑、临床医生)组成,所有成员均需签署利益冲突声明。
工作组参照此前指南评级工具的调查[19],检索Medline(PubMed)、中国生物医学文献数据库、万方数据知识服务平台和中国知网收录的2017年1月至2021年12月发表指南质量评价工具和方法学文献(附件1,扫描本文首页二维码可浏览),检索、筛选和提取由两人一组独立进行,分歧通过讨论解决。工作组将基于现有工具的内容和属性进行聚类,并对条目进行初步的去重、凝练和合并。
工作组使用问卷星(https://www.wjx.cn/)制作调查问卷并收集专家意见。针对每个条目,参与调查的专家选择“同意”“不同意”或“不确定”。“同意”比例超过75%的条目纳入最终版本,其他条目将根据专家提出的建议进行修改,两轮德尔菲调查仍未达成共识的条目将被删除[24]。
工作组采用层次分析法确定条目权重[25]。本研究将STAR分为三层,STAR工具为最高层,评级领域作为中间层,领域包含的条目作为最底层。工作组通过邮件对专家进行领域和条目重要程度调查,对于评级领域所在中间层,请每名专家直接进行重要程度打分[26]。对于同一领域的各条目进行两两比较的重要程度打分[27]。工作组根据重要程度的调查结果,使用层次分析软件(网络层次分析法辅助软件 yaanp V2.3)构造判断矩阵,得到各领域权重和领域内各条目的权重。
工作组介绍前期概况性评价、德尔菲调查和层次分析法计算权重的结果,组织专家对条目和计分方法进行讨论,所有建议和意见都被记录和存档。工作组根据专家反馈修改条目并完善,经工作组全体同意形成STAR条目清单初稿。
测试的指南样本选择《2020中华医学会系列杂志发表指南评价报告》中发布的“2020中华医学会系列杂志综合得分Top50的中国指南”(以下简称Top50指南)[20]。其中“综合得分”采用美国医学科学院(Institute of Medicine,IOM)指南评价标准[1]、中国临床实践指南评价体系(AGREE‐China)[28]和RIGHT[7]3种工具的综合评价方式,综合得分的计算方法为AGREE‐China总分×40%+RIGHT总体报告率×100分×40%+IOM中选择“是”的条目比例×100分×20%[20]。
STAR工作组根据共识会议确定的条目和计分方法设计统一的评级表,评级总分的自动计算步骤和统计分析通过Office Excel 16.60软件执行。参与直接评级的人员由来自循证医学和指南研究领域,以及来自临床各专业的人员共同组成。采用随机数字表法从Top50指南中随机抽取10部指南,由4名具有指南制订和评价经验的方法学评价人员利用STAR工具对抽取指南进行打分。同时邀请全国具有学科和地域代表性的30名临床医师作为临床评级人员。该30名临床专家均参加过指南方法学培训并通过考核[21]。采用随机数字表法随机将临床评级人员分为A、B、C、D、E 5组。研究人员根据50部指南的排名顺序抽样,等分为5份,交由各组6名人员评级,每组内的临床评级人员独立评价10部指南。为保障临床评级人员结果的可靠性,统计分析时,每组将排除1名和其他人员一致性最低的临床评级人员结果。对于每部指南的具体条目,如果其中≥3名临床评级人员均选择符合或部分符合条目的要求,即“1”,则该条目的结果定为“1”,否则定为“0”,所有条目得分之和为指南STAR得分。
1.内在信度:是指领域内的条目是否测量的是同一概念,条目之间是否具有内在一致性。用SPSS 26.0软件针对“其他领域(条目数<2)”外的10个领域评估STAR的内在信度(内部一致性),计算Cronbach′s α系数值。≥0.7提示一致性可接受,一致性越高代表条目的内在信度越高。对于是否需要删除领域内的某条目,通过校正项的总体相关性(corrected item-total correlation)进行判断,如果该值<0.3,代表条目与总体相关性较低,可考虑删除该条目以提高内在信度,并重新计算已删除后的Cronbach′s α系数值,如果明显高于总体Cronbach′s α系数,应考虑将对应项进行删除处理[29]。
2.评价者间信度:是指评级员间评级的一致性。用SPSS 26.0软件计算Cohen′s kappa系数值评估评价者间信度,系数值范围为-1~1,系数值越高,一致性较强,其中系数值>0.6提示一致性较强,系数值≤0.2提示一致性较差[30]。
3.内容效度:是指条目确定其在多大程度上代表了所要评价的指南质量。用Office Excel 16.60软件计算内容效度指数(content validity index,CVI)对STAR各条目和整体的内容效度进行评估。临床评级人员在完成10部指南的评级后,就每一条目对指南评级的重要性作出评价,也可提出修改、删除或增补条目的意见。重要性代表条目对指南评价的重要程度,范围为1~5分,对评级的重要性随分值依次递增。1分认为该条目最不重要,不纳入评级条目清单,5分认为该条目至关重要,应纳入清单。临床评级人员对每个条目的重要性用平均值表示。就每一条目给出评分为4或5(表示重要性较高,必须纳入工具)的评级人员数除以评级人员总数30,即为相应条目内容效度指数(item-level CVI,I-CVI)。所有条目I-CVI的平均值即为量表水平的内容效度指数(scale-level CVI,S-CVI)。当I-CVI≥0.78且S-CVI≥0.90时,即可认为研究工具的内容效度较好;当I-CVI<0.78时,提示研究人员需要根据评级意见认真修改、删除或增补条目,再次计算I-CVI与S-CVI[31]。
4.效标效度:以此前研究中的“综合得分”计算作为效标[20],效标效度指评级得分与“综合得分”之间的相关程度。用Office Excel软件提供的线性回归模型拟合STAR评级得分和综合得分,综合得分作为自变量,STAR评级得分作为因变量,根据决定系数(coefficient of determination,R2)评价拟合度的高低,范围为0~1,其中R2≥0.75提示拟合度良好,拟合度越高代表效标效度越高[32]。
5.易用性评估:本研究对临床评级人员进行条目重要性调查的同时,也进行了条目易用性评估。易用性评估代表条目使用的难易程度,评分范围为1~5分。1分认为评级最复杂,难以掌握,5分认为评级最容易,可快速掌握。对于临床评级人员对每个条目易用性评分用平均值表示。此外,临床评级人员需报告评级每部指南的平均用时(min),以及STAR使用和推广建议。
共有来自15个省级行政区(省或直辖市)34个专业的79位专家参与了STAR的研发和验证工作。
工作组纳入了关注指南评价不同维度的7种指南评价工具[1,6, 7,13, 14,33, 34]和1篇指南评价方法学文章[15]初步整理出针对指南科学性、透明性和适用性三个维度相关的42个评级条目,归为11个评级领域(附件2,扫描本文首页二维码可浏览)。
第一轮德尔菲专家调查,共39个条目达成共识,工作组根据专家提出的36条意见和建议修改了部分条目内容后,进行第二轮德尔菲专家调查,仍然有3个条目未达成共识(“提供所有参与人员的利益冲突声明表”“对相关指南进行系统评价”和“提供不同语言版本的指南”),从而未被纳入(附件2)。最终形成了包含11个领域39个条目的评级工具(表1)。
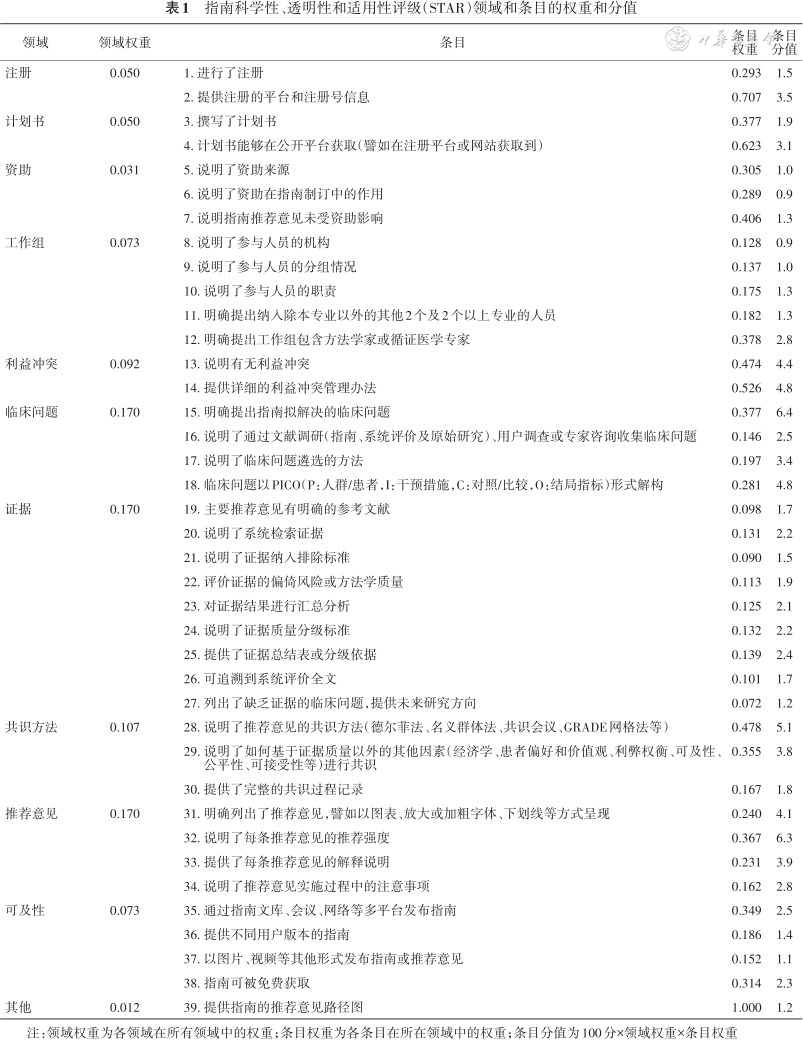
指南科学性、透明性和适用性评级(STAR)领域和条目的权重和分值
指南科学性、透明性和适用性评级(STAR)领域和条目的权重和分值
| 领域 | 领域权重 | 条目 | 条目权重 | 条目分值 |
|---|---|---|---|---|
| 注册 | 0.050 | 1. 进行了注册 | 0.293 | 1.5 |
| 2. 提供注册的平台和注册号信息 | 0.707 | 3.5 | ||
| 计划书 | 0.050 | 3. 撰写了计划书 | 0.377 | 1.9 |
| 4. 计划书能够在公开平台获取(譬如在注册平台或网站获取到) | 0.623 | 3.1 | ||
| 资助 | 0.031 | 5. 说明了资助来源 | 0.305 | 1.0 |
| 6. 说明了资助在指南制订中的作用 | 0.289 | 0.9 | ||
| 7. 说明指南推荐意见未受资助影响 | 0.406 | 1.3 | ||
| 工作组 | 0.073 | 8. 说明了参与人员的机构 | 0.128 | 0.9 |
| 9. 说明了参与人员的分组情况 | 0.137 | 1.0 | ||
| 10. 说明了参与人员的职责 | 0.175 | 1.3 | ||
| 11. 明确提出纳入除本专业以外的其他2个及2个以上专业的人员 | 0.182 | 1.3 | ||
| 12. 明确提出工作组包含方法学家或循证医学专家 | 0.378 | 2.8 | ||
| 利益冲突 | 0.092 | 13. 说明有无利益冲突 | 0.474 | 4.4 |
| 14. 提供详细的利益冲突管理办法 | 0.526 | 4.8 | ||
| 临床问题 | 0.170 | 15. 明确提出指南拟解决的临床问题 | 0.377 | 6.4 |
| 16. 说明了通过文献调研(指南、系统评价及原始研究)、用户调查或专家咨询收集临床问题 | 0.146 | 2.5 | ||
| 17. 说明了临床问题遴选的方法 | 0.197 | 3.4 | ||
| 18. 临床问题以PICO(P:人群/患者,I:干预措施,C:对照/比较,O:结局指标)形式解构 | 0.281 | 4.8 | ||
| 证据 | 0.170 | 19. 主要推荐意见有明确的参考文献 | 0.098 | 1.7 |
| 20. 说明了系统检索证据 | 0.131 | 2.2 | ||
| 21. 说明了证据纳入排除标准 | 0.090 | 1.5 | ||
| 22. 评价证据的偏倚风险或方法学质量 | 0.113 | 1.9 | ||
| 23. 对证据结果进行汇总分析 | 0.125 | 2.1 | ||
| 24. 说明了证据质量分级标准 | 0.132 | 2.2 | ||
| 25. 提供了证据总结表或分级依据 | 0.139 | 2.4 | ||
| 26. 可追溯到系统评价全文 | 0.101 | 1.7 | ||
| 27. 列出了缺乏证据的临床问题,提供未来研究方向 | 0.072 | 1.2 | ||
| 共识方法 | 0.107 | 28. 说明了推荐意见的共识方法(德尔菲法、名义群体法、共识会议、GRADE网格法等) | 0.478 | 5.1 |
| 29. 说明了如何基于证据质量以外的其他因素(经济学、患者偏好和价值观、利弊权衡、可及性、公平性、可接受性等)进行共识 | 0.355 | 3.8 | ||
| 30. 提供了完整的共识过程记录 | 0.167 | 1.8 | ||
| 推荐意见 | 0.170 | 31. 明确列出了推荐意见,譬如以图表、放大或加粗字体、下划线等方式呈现 | 0.240 | 4.1 |
| 32. 说明了每条推荐意见的推荐强度 | 0.367 | 6.3 | ||
| 33. 提供了每条推荐意见的解释说明 | 0.231 | 3.9 | ||
| 34. 说明了推荐意见实施过程中的注意事项 | 0.162 | 2.8 | ||
| 可及性 | 0.073 | 35. 通过指南文库、会议、网络等多平台发布指南 | 0.349 | 2.5 |
| 36. 提供不同用户版本的指南 | 0.186 | 1.4 | ||
| 37. 以图片、视频等其他形式发布指南或推荐意见 | 0.152 | 1.1 | ||
| 38. 指南可被免费获取 | 0.314 | 2.3 | ||
| 其他 | 0.012 | 39. 提供指南的推荐意见路径图 | 1.000 | 1.2 |
注:领域权重为各领域在所有领域中的权重;条目权重为各条目在所在领域中的权重;条目分值为100分×领域权重×条目权重
基于重要程度的调查结果,通过层次分析法确定了11个领域的权重以及各条目权重。其中“临床问题”“证据”和“推荐意见”领域的权重最高,达到0.170,最低的领域为“其他”,权重为0.012,其他7个领域和具体条目的权重见表1。
参与共识会议的专家均未提出增减条目的意见,工作组根据其他意见修改了部分条目的措辞,最终清单如表1所示。共识会议确定了STAR评级的方法,即由两人分别独立进行评级并核对结果。评级人员依据指南全文独立判断是否满足各条目,如果满足或部分满足的条目均表示为“1”,不满足或条目不适用均表示为“0”。条目满分为100分,如果条目表示“1”,则计入条目分值Ii(条目i分值=100分×领域权重×条目权重,表1)。如果表示为“0”,则不计入条目分值,所有条目分值之和为该指南的评级总分,即:。
1.内在信度:对于可以进行内在信度测试的领域,“注册”领域的Cronbach′s α系数值最高,达到1.000,一致性好,其次是“临床问题”“工作组”“证据”和“计划书”领域,系数值从0.737到0.763,一致性可接受。每个领域的Cronbach′s α系数值详见表2。
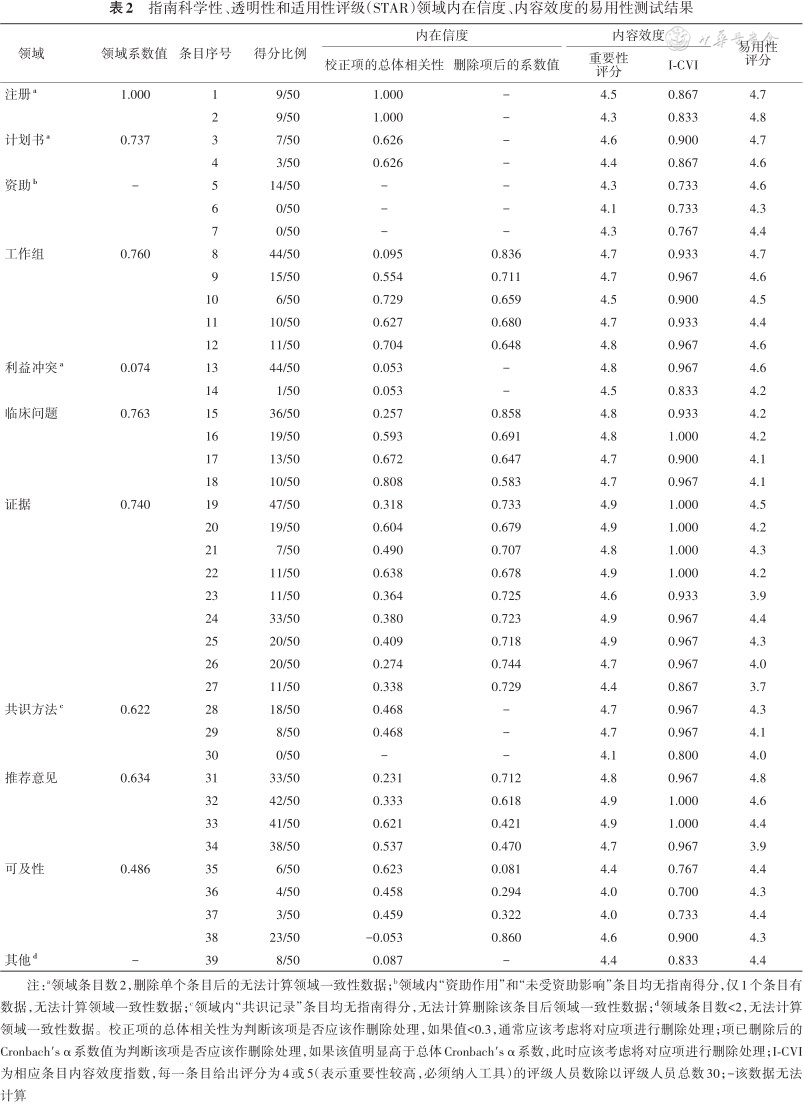
指南科学性、透明性和适用性评级(STAR)领域内在信度、内容效度的易用性测试结果
指南科学性、透明性和适用性评级(STAR)领域内在信度、内容效度的易用性测试结果
| 领域 | 领域系数值 | 条目序号 | 得分比例 | 内在信度 | 内容效度 | 易用性 评分 | ||
|---|---|---|---|---|---|---|---|---|
| 校正项的总体相关性 | 删除项后的系数值 | 重要性 评分 | I-CVI | |||||
| 注册a | 1.000 | 1 | 9/50 | 1.000 | - | 4.5 | 0.867 | 4.7 |
| 2 | 9/50 | 1.000 | - | 4.3 | 0.833 | 4.8 | ||
| 计划书a | 0.737 | 3 | 7/50 | 0.626 | - | 4.6 | 0.900 | 4.7 |
| 4 | 3/50 | 0.626 | - | 4.4 | 0.867 | 4.6 | ||
| 资助b | - | 5 | 14/50 | - | - | 4.3 | 0.733 | 4.6 |
| 6 | 0/50 | - | - | 4.1 | 0.733 | 4.3 | ||
| 7 | 0/50 | - | - | 4.3 | 0.767 | 4.4 | ||
| 工作组 | 0.760 | 8 | 44/50 | 0.095 | 0.836 | 4.7 | 0.933 | 4.7 |
| 9 | 15/50 | 0.554 | 0.711 | 4.7 | 0.967 | 4.6 | ||
| 10 | 6/50 | 0.729 | 0.659 | 4.5 | 0.900 | 4.5 | ||
| 11 | 10/50 | 0.627 | 0.680 | 4.7 | 0.933 | 4.4 | ||
| 12 | 11/50 | 0.704 | 0.648 | 4.8 | 0.967 | 4.6 | ||
| 利益冲突a | 0.074 | 13 | 44/50 | 0.053 | - | 4.8 | 0.967 | 4.6 |
| 14 | 1/50 | 0.053 | - | 4.5 | 0.833 | 4.2 | ||
| 临床问题 | 0.763 | 15 | 36/50 | 0.257 | 0.858 | 4.8 | 0.933 | 4.2 |
| 16 | 19/50 | 0.593 | 0.691 | 4.8 | 1.000 | 4.2 | ||
| 17 | 13/50 | 0.672 | 0.647 | 4.7 | 0.900 | 4.1 | ||
| 18 | 10/50 | 0.808 | 0.583 | 4.7 | 0.967 | 4.1 | ||
| 证据 | 0.740 | 19 | 47/50 | 0.318 | 0.733 | 4.9 | 1.000 | 4.5 |
| 20 | 19/50 | 0.604 | 0.679 | 4.9 | 1.000 | 4.2 | ||
| 21 | 7/50 | 0.490 | 0.707 | 4.8 | 1.000 | 4.3 | ||
| 22 | 11/50 | 0.638 | 0.678 | 4.9 | 1.000 | 4.2 | ||
| 23 | 11/50 | 0.364 | 0.725 | 4.6 | 0.933 | 3.9 | ||
| 24 | 33/50 | 0.380 | 0.723 | 4.9 | 0.967 | 4.4 | ||
| 25 | 20/50 | 0.409 | 0.718 | 4.9 | 0.967 | 4.3 | ||
| 26 | 20/50 | 0.274 | 0.744 | 4.7 | 0.967 | 4.0 | ||
| 27 | 11/50 | 0.338 | 0.729 | 4.4 | 0.867 | 3.7 | ||
| 共识方法c | 0.622 | 28 | 18/50 | 0.468 | - | 4.7 | 0.967 | 4.3 |
| 29 | 8/50 | 0.468 | - | 4.7 | 0.967 | 4.1 | ||
| 30 | 0/50 | - | - | 4.1 | 0.800 | 4.0 | ||
| 推荐意见 | 0.634 | 31 | 33/50 | 0.231 | 0.712 | 4.8 | 0.967 | 4.8 |
| 32 | 42/50 | 0.333 | 0.618 | 4.9 | 1.000 | 4.6 | ||
| 33 | 41/50 | 0.621 | 0.421 | 4.9 | 1.000 | 4.4 | ||
| 34 | 38/50 | 0.537 | 0.470 | 4.7 | 0.967 | 3.9 | ||
| 可及性 | 0.486 | 35 | 6/50 | 0.623 | 0.081 | 4.4 | 0.767 | 4.4 |
| 36 | 4/50 | 0.458 | 0.294 | 4.0 | 0.700 | 4.3 | ||
| 37 | 3/50 | 0.459 | 0.322 | 4.0 | 0.733 | 4.4 | ||
| 38 | 23/50 | -0.053 | 0.860 | 4.6 | 0.900 | 4.3 | ||
| 其他d | - | 39 | 8/50 | 0.087 | - | 4.4 | 0.833 | 4.4 |
注:a领域条目数2,删除单个条目后的无法计算领域一致性数据;b领域内“资助作用”和“未受资助影响”条目均无指南得分,仅1个条目有数据,无法计算领域一致性数据;c领域内“共识记录”条目均无指南得分,无法计算删除该条目后领域一致性数据;d领域条目数<2,无法计算领域一致性数据。校正项的总体相关性为判断该项是否应该作删除处理,如果值<0.3,通常应该考虑将对应项进行删除处理;项已删除后的Cronbach′s α系数值为判断该项是否应该作删除处理,如果该值明显高于总体Cronbach′s α系数,此时应该考虑将对应项进行删除处理;I-CVI为相应条目内容效度指数,每一条目给出评分为4或5(表示重要性较高,必须纳入工具)的评级人员数除以评级人员总数30;-该数据无法计算
2.评价者间信度:4名方法学评级人员的Cohen′s kappa系数值范围为0.716~0.802,算术平均值0.783,提示一致性较强,评级人员间的具体Cohen′s kappa系数值见附件3-1(扫描本文首页二维码可浏览)。临床评级人员组内Cohen′s kappa系数值范围为0.386~0.924,算术平均值0.579,提示一致性中等。每组排除一名评级员后,Cohen′s kappa系数值范围为0.406~0.924,算术平均值0.618,提示一致性较强。所有组评级人员间的具体Cohen′s kappa系数值见附件3-2~4-5(扫描本文首页二维码可浏览)。
1.内容效度:临床评级人员对STAR评级条目的重要性评估结果显示,条目32“说明了每条推荐意见的推荐强度”和条目33“提供了每条推荐意见解释说明”重要性得分并列最高,超过4.9分,条目36“提供不同多用户版本的指南”和条目37“以图片、视频等其他形式发布指南或推荐意见”重要性得分并列最低,为4.0分,重要性得分的算术平均值为4.6分。临床评级人员共计对评级条目提出了21条修改和删除意见。内容效度指数计算结果显示资助领域的全部3个条目,以及“可及性”领域的条目35、36和37的I-CVI均<0.78时,提示研究人员需要根据意见进行修改或删除。STAR总体S-CVI为0.905,提示整体内容效度良好。各条目重要性评分和I-CVI详见表2。
2. STAR评级得分和效标效度测试:Top50指南的STAR评级得分最高为93.7分,最高分和最低分极差为49.9分,指南样本的具体STAR评级得分见附件4(扫描本文首页二维码可浏览)。指南综合得分和STAR评级得分两者之间的线性回归方程为y=1.07x-16.47(x为综合得分,y为STAR评级得分),R2为0.76,R2>0.75,提示STAR的效标效度良好。
对于临床评级人员对STAR评级条目的易用性评估,条目21“提供注册的平台和注册号信息”易用性得分最高,为4.8分,条目27“报告缺少证据支持的研究问题,提供未来研究方向”易用性得分最低,为3.7分,易用性得分的算术平均值为4.3分,各条目易用性评分详见表2。临床评级人员报告的评级每部指南的用时为10~60 min,中位用时20 min,四分位间距5 min。临床评级人员对STAR使用和推广提出了55条建议,研究人员进行了对应性修改和完善。
为满足针对中国指南综合评价的需要,STAR工作组研制了指南科学性、透明性和适用性的多维度评级工具,包含赋予不同权重的11个领域和39个条目,较之于现有的评价工具,更加系统和全面。STAR首次对评级领域和条目赋予了不同权重,根据自动公式快速计算得出指南总体得分,得分的高低对应指南排名。
国内外现有的指南评价工具,仅17%报告了工具的信度或效度的验证结果[6,16]。由美国国立指南文库(National Guideline Clearinghouse,NGC)基于AGREE和IOM标准研制的NGC可信赖标准的依从性(National Guideline Clearinghouse Extent of Adherence to Trustworthy Standards,NEATS)是验证相对比较全面的工具,但相比STAR未进行内在信度、结构效度、校标效度和临床评级人员的易用性调查等[35]。
在STAR内在信度测试中,“注册”领域的一致性显示最好,原因为指南在满足“注册”领域中的注册条目同时,也必定会提供注册信息;“临床问题”“工作组”“证据”和“计划书”领域,基本反映相同方面的信息,一致性较高;“推荐意见”领域的前两个条目主要反映报告的透明性,后两个条目更多依赖指南方法的严谨性,因此本领域的一致性欠佳;“利益冲突”领域的一致性欠佳,主要原因是指南进行利益冲突管理比例过低,而报告无利益冲突比例非常高;“可及性”领域删除条目38“指南可被免费获取”条目后,系数值明显提升,提示该条目相比本领域其他3个条目可能更多依赖于发布杂志的政策。根据内在测试结果,可考虑删除某些领域的条目,但考虑STAR目前的领域和条目是由专家组经过共识后确定的,若要最终删除,还需满足以下两项条件:(1)在更大样本测试中,条目校正的项总计相关性仍然<0.3或领域Cronbach′s α系数值<0.5;(2)STAR更新时取得2/3共识组专家的同意。在评价者间信度测试中,方法学评级人员STAR评级的一致性较好,也高于NEATS评价员间的一致性(加权kappa值0.73),可能原因是方法学评级人员对指南方法学较为熟悉,具有较丰富的指南制订和评价经验。
对于效度测试,STAR内容效度评估结果显示每个条目至少有70%的临床评级人员认为必须纳入,整体的内容效度指数达90%,与STAR工作组在研制过程中专家对重要性的判断基本符合,与NEATS内容效度水平(80%~100%)也基本一致。STAR条目中关于指南“资助”和“可及性”领域的6个条目内容效度较低,反映出中国指南对资助和可及性关注较低,也符合之前评价的结果[12,20]。对于这些条目,若要最终删除,也需满足:(1)在更大样本测试中,修改后条目再次计算的I-CVI仍然<0.78;(2)取得2/3共识组专家的同意。效标效度测试中,指南样本的STAR评级结果和综合得分的线性回归方程的拟合度良好,效度较高,可考虑作为多种评价工具综合得分的替代方式。
对于STAR评级效率,原有的综合评价需要同时采用两种或以上评价工具,也面临不同评价工具结果分配权重和综合得分计算问题,影响评价效率[36, 37, 38]。例如,已发表的“2020中华医学会系列杂志发表指南评价报告”,需要由方法学评价组、临床评价组和质量控制组共58名成员完成,平均每部指南需经3名成员采用3种评价工具评价,以及1名成员进行结果核查。综合得分计算由3名成员讨论确定。STAR评级仅需一种评价工具,设计每部指南仅需2人参与判断条目是否满足,临床评级人员中位用时仅20 min,评价效率明显提升,相比方法学评价人员使用单个NEATS工具平均花费2~3 h评价指南也大大缩短[35]。条目易用性调查总体评分较低,原因可能包括:(1)临床评级员对STAR的评级方法比较生疏,需要更多培训和练习;(2)缺乏对评价条目的解释性文件;(3)样本指南未严格遵循指南报告规范,内容报告不全面[20],评级人员无法便捷获得评级所需信息。
未来STAR工作组将开展以下相关工作:(1)进一步开展信效度验证和易用性测试;(2)采用STAR工具定期对中国指南进行评级;(3)制作包含详细条目解释和分级指导的手册,开展相关讲座或培训;(4)与国际同行开展合作,将STAR工具推广至其他国家。
本研究存在以下局限性:(1)参与研发和验证的人员未包含国际专家,主要原因是STAR项目目前主要针对中国的指南进行评级,测试的指南样本也绝大部分非英文发表;(2)评级测试样本仅基于期刊发表的指南及其链接的附件,对于未发表和未在网络上公开的信息没有进行收集,可能影响STAR的部分结果。
STAR的研发完善了指南的评价体系,具有良好的信效度,提升了指南评级人员的效率,可用于指南的综合评价和分级,进而推动高质量指南的制订、传播和应用。

以下人员参与了STAR研发和验证的相关工作(按姓氏笔画排序):于长禾(北京中医药大学东直门医院推拿疼痛科);马京梅(北京大学第一医院产科);王宇峰(上海交通大学医学院附属第九人民医院口腔黏膜病科);王春燕(兰州大学学报编辑部);王蕾(浙江大学医学院附属儿童医院儿童保健科);方莹(西安交通大学附属儿童医院消化科);吕萌(重庆医科大学附属儿童医院);任相颖(武汉大学中南医院循证与转化医学中心);任梦娟(兰州大学公共卫生学院);刘云兰(兰州大学公共卫生学院);刘兰英(上海市精神卫生中心中医科;浙江省立同德医院情感障碍科);刘晓玉(天津中医药大学针灸推拿学院);刘容吉(北京协和医院药剂科);刘雅莉(国家儿童医学中心;首都医科大学附属北京儿童医院临床流行病学与循证医学中心);孙凤(北京大学循证医学中心;北京大学公共卫生学院流行病与卫生统计学系);孙雅佳(兰州大学公共卫生学院);李安(中国中医科学院中医临床基础医学研究所);李沁原(重庆医科大学附属儿童医院呼吸科);李舍予(四川大学华西医院内分泌代谢科);李建生(河南中医药大学);李博(首都医科大学附属北京中医医院/北京市中医药研究所临床流行病学与循证医学中心);李慧(广东省中医院针灸科);吴蕾(广州省中医院呼吸与危重症医学科);何乐人(中国医学科学院整形外科医院整形七科);张小杰(温州医科大学附属第二医院神经内科);张佳钰(上海交通大学医学院附属第九人民医院牙体牙髓科);张桂芳(北京医院国家老年医学中心);张蓉(武汉大学健康学院;十堰市太和医院);陈泽(广州中医药大学针灸康复临床医学院);罗旭飞(兰州大学公共卫生学院);罗征秀(重庆医科大学附属儿童医院呼吸科);岳丽青(中南大学湘雅医院护理部);周英凤(复旦大学护理学院;复旦大学JBI循证护理合作中心);周奇(兰州大学基础医学院循证医学中心);郑志杰(北京大学全球健康发展研究院;北京大学公共卫生学院);屈静晗(中国医学科学院 北京协和医学院 北京协和医院药剂科);孟玲慧(首都儿科研究所循证医学中心);姜永茂(中华医学会);秦晓宽(中国中医科学院望京医院脊柱二科);贾娜(北京医院心内科);夏乐(北京大学第一医院妇产科;中华围产医学杂志编辑部);倪小佳(广东省中医院脑病中心);徐东(南方医科大学卫生管理学院);徐潇(中国中医科学院中医临床基础医学研究所);高静韬(首都医科大学附属北京胸科医院;中国疾病预防控制中心结核病防治临床中心);曹玮(北京协和医院感染内科);常中飞(首都医科大学石景山教学医院/北京市石景山医院中医科);蒋艳芳(北京大学第三医院运动医学科);韩涛(中国中医科学院望京医院脊柱二科);焦丽雯(中国中医科学院中医临床基础医学研究所);褚红玲(北京大学第三医院临床流行病学研究中心);薄禄龙(海军军医大学第一附属医院麻醉科)
所有作者均声明不存在利益冲突

























