
Joinpoint回归模型分析是流行病学时间趋势分析的常用方法。本文以肿瘤发病时间趋势分析为例,从模型的基本原理、分析步骤、实例演示和注意事项等方面进行系统阐述,以期将模型的方法原理与操作实践有机结合,为读者开展类似的研究分析提供参考。


版权归中华医学会所有。
未经授权,不得转载、摘编本刊文章,不得使用本刊的版式设计。
除非特别声明,本刊刊出的所有文章不代表中华医学会和本刊编委会的观点。
经全国继续医学教育委员会批准,本刊开设继教专栏,每年从第4期至第12期共刊发9篇继教文章,文后附5道单选题,读者阅读后可扫描标签二维码答题,每篇可免费获得Ⅱ类继教学分0.5分,全年最多可获4.5分。
时间趋势分析是流行病学研究的重要组成部分[1]。传统的回归模型主要从全局的角度对研究时间范围内疾病分布的整体趋势进行拟合评价,无法呈现局部的变化特征。1998年Kim等[2]首次提出Joinpoint回归模型,该模型的核心思想是根据疾病分布的时间特征建立分段回归,通过若干连接点将研究时间分割成不同区间,并对每个区间进行趋势拟合和优化,进而更详细地评价全局时间范围内不同区间特异性的疾病变化特征。Joinpoint回归模型由美国国立癌症研究所肿瘤控制与人口科学部开发,在肿瘤发病率和死亡率趋势研究领域得到广泛地应用。本文将以肿瘤发病趋势分析为例,从基本原理、分析步骤、实例演示和注意事项四个方面展开阐述。
Joinpoint回归模型有线性模型(y=xb)和对数线性模型(ln y=xb)两种,如果因变量服从正态分布(或近似正态分布)且数据样本量较大(通常大于100)时选择线性模型;如果因变量服从指数分布或泊松分布,则宜选用对数线性模型。分析以人群为基础的肿瘤发病率和死亡率趋势时一般选择对数线性模型。假设有一组观测值y表示肿瘤发病率,x表示发病年份,n表示研究的时间跨度,以(x1,y1), …(xn,yn)表示,其中x1≤…≤xn,对数线性模型的回归方程式为:
式中,e为自然底数,k表示转折点的个数,τk表示未知的转折点,β0为不变参数,β1为回归系数,δk表示第k段分段函数的回归系数。当(x-τk)>0时,(x-τk)+)=x-τk,否则(x-τk)+)=0。
网格搜索法(grid search method, GSM)是Joinpoint默认采用的建模方法。GSM是将研究数据划分为网格,每个网格交点对应一个规划方案,然后在设定的区间内用固定步长逐点计算对应方程的性能指标,以确定最优函数[2, 3]。简言之,Joinpoint模型通过GSM法建立所有可能存在的区间分段函数连接点(即Joinpoint点),并计算每种可能的情况下所对应的误差平方和(sum of squares errors,SSE)和均方差(mean squared errors, MSE), 选择MSE最小的网格点为分段函数连接点,并根据选定的连接点和区间函数拟合β0、β1、δ1、... δk等方程参数。除了GSM法外,Joinpoint软件早期版本中还提供了Hudson′s 法的备选项,现已取消。
Monte Carlo置换检验(permutation test)是Joinpoint软件默认的模型优选方法。建模之前,需要先设定连接点k的数量范围kϵ(MIN, MAX), MIN表示最少连接点数,通常情况下可设为0;MAX表示最多连接点数。每一次置换检验会检验原假设H0:设连接点数量K=Ka以及备选假设H1:连接点数量k=kb。置换检验从ka=MIN和kb=MAX开始,如果拒绝H0,则设k=ka+1后再进行检验;如果不拒绝H0,则设k=kb-1后再次进行检验,直到ka=kb, 即k=ka=kb就是置换检验优选出的连接点数,其对应的模型即为最优模型[4]。因为置换检验相对耗时,为了兼顾运算速度和结果的稳定性,官方推荐和系统默认的置换检验的次数为4 500次,因为涉及多重检验,所以采用Bonferroni法对统计学显著水平进行校正。除Monte Carlo置换检验外,软件还提供了贝叶斯信息准则(bayesian information criterion,BIC)、校正贝叶斯信息准则(modified bayesian information criterion,MBIC)及相关衍生方法进行优选模型的筛选,但主要面向特殊需求的高级用户使用。
年度变化百分比(annual percent change, APC)和平均年度变化百分比(average annual percent change, AAPC)及95%CI是Joinpoint模型主要结果指标。顾名思义APC为因变量平均每年变化的百分比。例如对数线性模型ln(y)=β0+β1x, 其中y表示发病率,x表示发病年份,则拟合模型APC计算公式可推算为:
100(1-α)%可信区间下限和上限分别为:
式中,β1为回归系数,s为β1的标准误,d为自由度,td(q)是自由度d的 t分布对应第q百分位数(如95%)的数值。
APC用于评价分段函数各独立区间的内部趋势,或者连接点数量为0的全局趋势,如果要综合评价包含多个区间的全局平均变化趋势时就需要用AAPC。AAPC的参数计算方法是通过分段区间的跨度宽度w对各区间的回归系数进行加权计算而来,其公式为:
100(1-α)%可信区级下限和上限分别为:
式中,wi为每个分段函数的区间跨度宽度(即区间所包括的年度数),βi为每个区间对应的回归系数,为正态加权系数,为βi的方差,Zα为正态分布下第α百分位数的对应值。
下载Joinpoint软件需登录美国国立癌症研究所网站(https://surveillance.cancer.gov/joinpoint/download),注册提交申请信息后可下载并安装至本地电脑免费使用,软件定期更新,目前官方最新版本为Joinpoint 4.8.0.1(2020年4月发布)。
Joinpoint软件支持的可读入文件格式仅包括ASCII的后缀“.txt”文本和Excel spreadsheet的“.CSV”文件格式。读入数据可以通过SAS、Stata、SPSS、Excel或其他软件(如SEER*Stat)转换或导出。数据准备完成后通过Joinpoint软件打开,根据研究数据的不同类型选定因变量、自变量和分组变量读入软件中。因变量支持两种模式:一是提供已计算好的粗率、标化率、标准误等结果指标;二是提供各年龄组对应的病例频数、人口数和标化人口数等,由软件运行计算结果,再进行趋势分析。
一般情况下主要设置3个参数:(1)是否选用对数线性模型(log transformation),如何选择前文已阐述;(2)方差齐性的误差选项(heteroscedastic error option):假定研究数据方差稳定的情况下,可以选择“恒方差[constant variance(homoscedastic)]”;如果考虑方差变异较大时可选择“标准误[standard error(provided)]”或者“泊松(poisson variance)”。选择“标准误”的话需要提供或者计算标准误,选“泊松”的话仅支持因变量类型为频数和人口数的模式。粗率标准误的计算公式如下:
假定事件发生数(count)服从泊松分布,各年龄组i从年龄x到y岁,则标化发病率的标准误计算公式为:
式中stdpopi为i年龄组标准人口,counti为i年龄组事件频数,populationi为对应人口数。(3)连接点数量:连接点的数量与研究数据的时间跨度的宽度(观测值数量)有关,系统默认最小为0,最大为5,用户可根据需求自行定义。但连接点过多的话运算相当耗时,因此软件推荐的观测值数量与系统默认最大连接数量有如下的对应关系:观测值数量分别为0~6、7~11、12~16、17~21、22~26、≥27时,默认最大连接点数量分别为0、1、2、3、4、5。除上述参数外,软件还支持“模型选择方法(Model select Method)”“AAPC计算范围设定”“APC/AAPC 可信区间算法”“自相关误差选项(Auto Errors Options)”等参数选择,供有特殊需要的高级用户,具体需求可参照软件说明,一般情况下选择默认设置即可。
以美国SEER(Surveillance, Epidemiology, and End Results Program)数据库中1993—2003年结直肠癌年龄标化发病率变化趋势为例,分别采用因变量为“发病例数+人口数”和“标化发病率”两种模式进行演示。示例数据可登录https://surveillance.cancer.gov/joinpoint/age.html网页在线下载(注:本示例中的变量名和标签略作修改,原始数据无改动)。
示例数据库类型为txt格式,采用Joinpoint软件打开后可见,库中包含性别、诊断年份、年龄组别、年龄组发病、年龄组发病例数、年龄组人口数和年龄组标准人口数。数据读入环节因变量类型选择“Calculated From Data File”,根据软件的需要依次选择频数变量(Count Variable)、人口变量(Population Variable)、调整/标化变量(Adjustment Variable)和标准人口变量(Standard Variable),并设定自变量(Independent Variable)和分组变量(By Variables, 可选项),在系统默认的对数线性模型选择方差误差(Heteroscedastic Errors Option)选项为“Standard Error(Caculated)”即可运行(图1)。
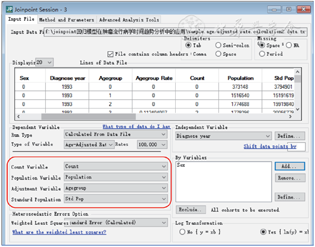
运算完毕后呈现结果如图2所示,左侧部分为模型的选择结果,本示例中0、1、2分别表示分组变量中的“男女合计”“男性”和“女性”,可以选择查看不同连接点数对应的模型,其中加星号的是系统优选推荐的模型;右侧主体窗口有“Graph”“Data”“Model Estimates”“Trend”和“Model Selection”五个选项,分别对应模型拟合的拐点/曲线图、计算/拟合的应变量数据、选定模型的参数指标、APC/AAPC和95%CI趋势指标,以及模型优选的置换检验情况。

以男女合计的发病率变化趋势结果为例,1993—2013年间SEER结直肠癌标化发病率分别在1995、1998和2008年出现三个拐点(连接点),对应4个区间的APC(95%CI)分别为APC1993-1995=-2.55(95%CI:-5.91~0.94,P=0.133)、APC1995-1998=1.92(95%CI:-1.52~5.48,P=0.245)、APC1998-2008=-2.37(95%CI:-2.67~-2.07,P<0.001)、APC2008-2013=-2.14(95%CI:-2.71~-1.56,P<0.001)],全局AAPC1993-2013=-3.87(95%CI:-4.64~-3.10,P<0.001)]。全局AAPC结果表明,1993—2013年间美国SEER结直肠癌发病率平均每年下降3.87%。最终优选的拟合模型回归方程为:
式中y为发病率,x为诊断年份,模型参数均可在Model Estimates选项中查阅。
将已下载的示例数据库作适当演算,生成以标化发病率作为因变量的读入数据类型,选择“恒方差”误差选项,参数设置如图3所示,即可运行。对比因变量为“发病例数+人口数”模式和因变量为“标化发病率”模式的分析结果,即“恒方差”和“标准误”不同误差选项的运行结果可以发现,两个结果中连接点的数量与位置完全一致,APC/AAPC及95%CI大小差异微小,提示研究数据的误差变异较小时,两种计算模式均可选择。见图4。
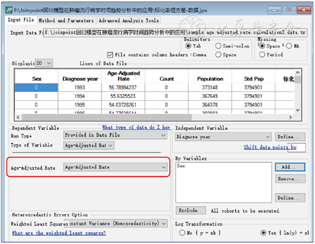
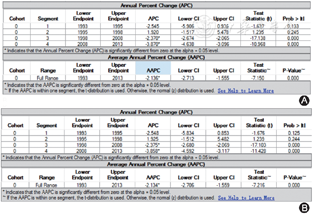
A: 因变量为“发病例数+人口数”的“标准误”误差选项; B:因变量为“标化发病率”的“恒方差”选项
Joinpoint模型主要用于时间序列数据的趋势变化特征分析,适用数据的因变量主要为事件数(病例数)、发病/死亡率或构成比等,数据分布类型符合正态分布、指数分布或者泊松分布时均可选用。该方法自提出以来在肿瘤流行病学领域得到广泛的应用[5, 6, 7]。Joinpoint软件定期更新迭代,不同版面的操作界面、变量要求、模型和参数估计方法等均存在差异和持续优化,用户在选用不同版本或者软件更新时需要留意。此外,软件逐步推出新的功能模块,如“Pairwise-Comparison”和“Jump Model/Comparability Ratio”等模块,供特殊需求者选用。
软件使用过程中有些细节值得注意:(1)在以发病率或死亡率为因变量模式进行分析时,会遇到某个观测值对应的率为0而导致模型拟合终止的情况发生。鉴于模型不支持率为0的数据,我们一般可将数值为0的应变量观测值替换为某个微小数据(如0.000 001或0.000 0001等,根据研究数据的实际情况决定)即可解决。(2)在进行率的趋势分析时,如果率的变化相对稳定,未出现明显的“大起”“大落”情况,提示研究数据的方差变异较小,此时可以选用操作简便的“恒方差”选项进行运算;如果率的变化情况复杂,或可能存在短时期内“骤升”“骤降”情况,那就需要采用“标准误”或者“泊松”选项。研究者可根据研究数据的客观情况进行不同选项的拟合结果筛选。(3)Joinpoint软件支持多个分组变量模式,如果研究结果的分层因素较多时,可以根据分层变量的逻辑关系将数据库整理成一个包含多层分组变量的分析数据库,这样可以一次运行输出所有情况的分层结果,避免了多次数据整理和分批运算输出等繁琐过程。
在开展疾病趋势分析时,研究时间的跨度不宜过短,一般至少要连续5年,最好达到连续达10年以上的时间跨度。如果时间跨度较短,研究结果受疾病分布的自身变异及监测数据的完整性质量等因素影响较大,很难获得客观的趋势变化特征。在做长期趋势分析的结果解读时,需要将连接点的分布位置、不同区间的趋势变化与疾病发生发展、防控政策措施等其他流行病学特征紧密结合,寻求趋势变化潜在的始动因素与合理解释,切忌盲目推崇模型的趋势结果。
Joinpoint模型设计和软件开发十分友好,SEER官网上提供详细的模型介绍和软件操作的在线信息和PDF文档,并设计了“手把手”的实操性案例分析。本文仅以肿瘤流行时间趋势分析为例为读者介绍了模型的方法原理与实践操作相关内容。除此之外,Joinpoint模型在传染病分析、疾病负担预测等方面也有拓展性的应用[8, 9]。
所有作者均声明不存在利益冲突
1. Joinpoint对数线性回归模型的方程式为:
A.
B.
C.
D.
2. Joinpoint回归分析时,自变量一般为:
A. 发病/死亡率
B. 事件数(病例数)
C. 时间变量(如年份)
D. 以上都不是
3. 以下哪个不是Heteroscedastic Error Option 的选项:
A. Constant Varinace (Homoscedasticity)
B. Standard Error (Calculated)
C. Poisson Variance
D. Grid Search
4. Joinpoint软件4.8.0.1版本推荐的优选模型的方法是:
A. Permutation Test
B. Data Driven BIC Methods
C. Traditional BIC Methods
D.Hudson's
5. APC和AAPC检验的统计量分别为:
A. t值,t值
B. t值,z值
C. z值,z值
D. t值,z值

























