
医疗卫生领域研究中常见的层次结构数据适用的3种统计模型包括混合线性模型(MLM)、广义估计方程(GEE)和广义线性混合模型(GLMM)。在IBM SPSS Statistics中,"混合模型"分析菜单下的"线性"和"广义线性"选项可分别实现MLM和GLMM,"广义线性模型"菜单下的"广义估计方程"可实现GEE。以IBM SPSS Statistics自带数据为例,展示在IBM SPSS Statistics 20.0中的实现并对主要结果进行解释,IBM SPSS Statistics可以简单地实现MLM、GEE和GLMM,3种方法考虑数据的聚集性并将误差分解到相应的层次水平,可以得到更为科学合理的结果,有利于广大医学研究者快速掌握并使用。


版权归中华医学会所有。
未经授权,不得转载、摘编本刊文章,不得使用本刊的版式设计。
除非特别声明,本刊刊出的所有文章不代表中华医学会和本刊编委会的观点。
老年人群常由多种因素造成多病共存,且老年医学关注的疾病现象往往要从宏观和微观层面去解释,因而层次结构数据(hierarchically structured data)在老年医学研究中较为常见。层次结构数据是指数据具有多个层级或多个水平,如卫生服务或流行病学调查,研究对象常常嵌套于地区、城乡、医院等不同级别中;纵向研究中,可把时间视为水平1单位,每个研究对象视为水平2单位;多中心临床试验或动物实验中,常将患者或动物视为水平1单位,试验中心或动物窝别视为水平2单位。层次结构数据中同一层级的个体间往往不具备独立性,若采用传统分析方法可能忽略高水平单位间变异,残差标准误被高估,且忽略了高水平单位对结局变量的影响[1]。本文旨在介绍老年医学研究中层次结构数据适用的3种统计模型,这些模型通过拟合与数据层次结构相适应的复杂误差结构,并估计相应的残差方差及协方差,提高了模型估计的准确度[1,2,3]。本文采用IBM SPSS Statistics自带数据展示其在IBM SPSS Statistics 20.0中的实现过程和结果呈现,以期为医学科研人员正确运用此法提供便捷可行的途径。
将单一的随机误差项分解到与数据层次结构对应的各水平上,估计相应的残差方差及协方差。借此,模型既可解释个体变异,也可估计高水平随机效应,提供高水平单位潜在的总体特征信息[4,5,6]。
在模型中引入作业相关矩阵,计算各次测量值两两之间的相关性,得到稳健的参数估计值,亦适用于处理观察次数不等、观察时间间隔不等的非平衡设计数据[7]。

例1:16例患者接受为期6个月的新饮食,测量其对有心脏疾病家族史患者体重的影响,干预前和干预后共测量5次体重[8],该数据来自SPSS安装目录下的Samples\English文件夹内的dietstudy.sav,为拟合混合线性模型,更改其数据格式见表2,其中测量次数为1、2、3、4、5分别代表第5次、第4次、第3次、第2次以及第1次测量,SPSS实现步骤如表3。其中,第②步选的是非结构化,表示对观测值之间的相关性不做任何限定,让模型根据资料特征自动估计。
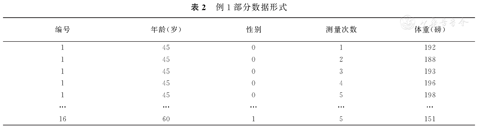
例1部分数据形式
例1部分数据形式
| 编号 | 年龄(岁) | 性别 | 测量次数 | 体重(磅) |
|---|---|---|---|---|
| 1 | 45 | 0 | 1 | 192 |
| 1 | 45 | 0 | 2 | 188 |
| 1 | 45 | 0 | 3 | 193 |
| 1 | 45 | 0 | 4 | 196 |
| 1 | 45 | 0 | 5 | 198 |
| … | … | … | … | … |
| 16 | 60 | 1 | 5 | 151 |

混合线性模型SPSS实现
混合线性模型SPSS实现
| 分析步骤 | 说明 |
|---|---|
| ①"分析(analyze)"→"混合模型(mixed models)"→"线性(linear)" | 选择SPSS软件中的"混合线性模块" |
| ②"指定主体和重复(specify subjects and repeated)":编号放入"主体(subjects)"框,测量次数放入"重复(repeated)"框,"重复协方差类型(repeated covariance type)"选择"非结构化(unstructured)" | 指定数据层次结构和重复测量协方差类型 |
| ③"因变量(dependent variable)":体重,"因子(factor)":测量次数 | 指定结局变量和自变量 |
| ④"固定效应(fixed effects)":选择测量次数添加入"模型(model)"框中→"继续(continue)" | 指定固定效应 |
| ⑤"随机(random)":直接点击"继续(continue)" | 指定随机效应 |
| ⑥"统计(statistics)":选择"固定效应的参数估算值(parameter estimates)""协方差参数检验(tests for covariance parameters)"→"确定(ok)" | 指定参数估计及检验 |
表4为参数估计结果,可以看出相对于第1次测量,每次测量的体重变化均有统计学意义。且任意2次测量间都是有相关性的,即数据具有层次结构。
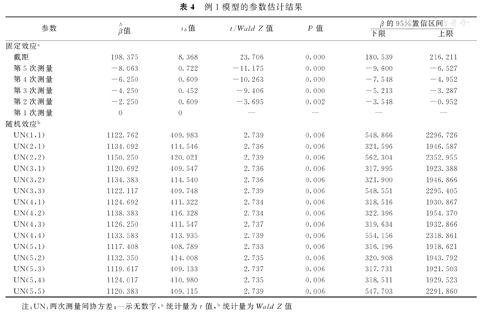
例1模型的参数估计结果
例1模型的参数估计结果
| 参数 |  值 值 | sb值 | t/Wald Z值 | P值 | β的95%置信区间 | ||
|---|---|---|---|---|---|---|---|
| 下限 | 上限 | ||||||
| 固定效应a | |||||||
| 截距 | 198.375 | 8.368 | 23.706 | 0.000 | 180.539 | 216.211 | |
| 第5次测量 | -8.063 | 0.722 | -11.175 | 0.000 | -9.600 | -6.527 | |
| 第4次测量 | -6.250 | 0.609 | -10.263 | 0.000 | -7.548 | -4.952 | |
| 第3次测量 | -4.250 | 0.452 | -9.406 | 0.000 | -5.213 | -3.287 | |
| 第2次测量 | -2.250 | 0.609 | -3.695 | 0.002 | -3.548 | -0.952 | |
| 第1次测量 | 0 | 0 | — | — | — | — | |
| 随机效应b | |||||||
| UN(1,1) | 1122.762 | 409.983 | 2.739 | 0.006 | 548.866 | 2296.726 | |
| UN(2,1) | 1134.092 | 414.546 | 2.736 | 0.006 | 321.596 | 1946.587 | |
| UN(2,2) | 1150.250 | 420.021 | 2.739 | 0.006 | 562.304 | 2352.955 | |
| UN(3,1) | 1120.692 | 409.547 | 2.736 | 0.006 | 317.995 | 1923.388 | |
| UN(3,2) | 1134.383 | 414.540 | 2.736 | 0.006 | 321.900 | 1946.866 | |
| UN(3,3) | 1122.117 | 409.748 | 2.739 | 0.006 | 548.551 | 2295.405 | |
| UN(4,1) | 1124.692 | 411.322 | 2.734 | 0.006 | 318.516 | 1930.867 | |
| UN(4,2) | 1138.383 | 416.328 | 2.734 | 0.006 | 322.396 | 1954.370 | |
| UN(4,3) | 1126.250 | 411.547 | 2.737 | 0.006 | 319.634 | 1932.866 | |
| UN(4,4) | 1133.583 | 413.935 | 2.739 | 0.006 | 554.156 | 2318.861 | |
| UN(5,1) | 1117.408 | 408.789 | 2.733 | 0.006 | 316.196 | 1918.621 | |
| UN(5,2) | 1132.350 | 414.008 | 2.735 | 0.006 | 320.908 | 1943.792 | |
| UN(5,3) | 1119.617 | 409.133 | 2.737 | 0.006 | 317.731 | 1921.503 | |
| UN(5,4) | 1124.017 | 410.980 | 2.735 | 0.006 | 318.511 | 1929.523 | |
| UN(5,5) | 1120.383 | 409.115 | 2.739 | 0.006 | 547.703 | 2291.860 | |
注:UN:两次测量间协方差;—示无数字,a统计量为t值,b统计量为Wald Z值
例2:一项空气污染对儿童健康影响的纵向研究,旨在分析儿童年龄和母亲吸烟情况对儿童喘鸣的影响[9],收集俄亥俄州儿童在7、8、9和10岁的喘鸣症状及母亲在研究第1年吸烟情况。该数据来自SPSS安装目录下的Samples\English文件夹内的wheeze_steubenville.sav,包含如下变量:(1)id:儿童编号;(2)age:测量时儿童的年龄;(3)wheeze:测量时儿童喘鸣状况,0为无,1为有;(4)smoker:母亲在研究第1年的吸烟情况,0为不吸烟,1为吸烟;SPSS实现步骤见表5。表6给出了参数估计结果,无足够理由表明母亲吸烟影响儿童喘鸣发生(P=0.143),低年龄组(7~9岁组)相对于10岁组而言,喘鸣发生概率更高。作业相关矩阵是对观测值之间相关性的设定,可通过准似然独立准则(Quasi likelihood under independence model criteria,QIC)优选合适的作业相关矩阵,QIC值越小模型越合适[7],此外,在SPSS中广义估计方程无法对残差进行深入分解[10]。

重复测量数据的广义估计方程的SPSS实现
重复测量数据的广义估计方程的SPSS实现
| 分析步骤 | 说明 |
|---|---|
| ①"分析(analyze)"→ "广义线性模型(generalized linear models)"→ "广义估算方程(generalized estimating equations)" | 选择SPSS软件中的广义估计方程模块 |
| ②"重复(repeated)":将编号选入"主体变量(subjects variables)"框,年龄选入"主体内变量(within-subject variables)"框,"工作相关性矩阵(working correlation matrix)"选择"非结构化(unstructured)" | 指定数据层次结构和重复度量变量及重复测量间的相关性 |
| ③"模型类型(type of model)":选择"二元Logistic(binary logistic)" | 选择连接函数为二分类Logistic |
| ④"响应(response)":将喘鸣状况选入"因变量(dependent variable)"框 | 指定结局变量 |
| ⑤"预测变量(predictors)":将母亲吸烟情况和年龄选入"因子(factors)"框 | 指定自变量 |
| ⑥"模型(model)":将母亲吸烟情况和年龄选入"模型(model)"框 | 指定主效应(此部分也可以根据研究需要拟合交互效应) |
| ⑦"估算(estimation)":默认即可 | 对模型的估计方法进行设定 |
| ⑧"统计(statistics)":选择"工作相关性矩阵(working correlation matrix)",其余默认即可 | 指定估计的参数结果和工作相关矩阵 |
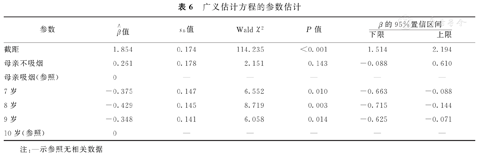
广义估计方程的参数估计
广义估计方程的参数估计
| 参数 |  值 值 | sb值 | Waldχ2 | P值 | β的95%置信区间 | |
|---|---|---|---|---|---|---|
| 下限 | 上限 | |||||
| 截距 | 1.854 | 0.174 | 114.235 | <0.001 | 1.514 | 2.194 |
| 母亲不吸烟 | 0.261 | 0.178 | 2.151 | 0.143 | -0.088 | 0.610 |
| 母亲吸烟(参照) | 0 | — | — | — | — | — |
| 7岁 | -0.375 | 0.147 | 6.552 | 0.010 | -0.663 | -0.088 |
| 8岁 | -0.429 | 0.145 | 8.719 | 0.003 | -0.715 | -0.144 |
| 9岁 | -0.348 | 0.141 | 6.058 | 0.014 | -0.625 | -0.071 |
| 10岁(参照) | 0 | — | — | — | — | — |
注:—示参照无相关数据
例3:某地为了解某新教学方法能否有效提升学生成绩,采用简单随机抽样选取23所学校,并随机抽取不同班级分为试验组和对照组,在新学年分别应用新教学法和常规教学法进行教学,学生在学年初和学年末各考试1次[11];此数据有3个层次:学校、班级和学生(本数据为IBM SPSS Statistics自带数据,名为test_scores.sav,文件位置同例1)。SPSS实现步骤见表7。广义线性混合模型的输出结果需要双击阅读详细内容。

例3模型的SPSS实现
例3模型的SPSS实现
| 分析步骤 | 说明 |
|---|---|
| ①"分析(analyze)"→ "混合模型(mixed models)"→"广义线性(generalized linear)" | 选择SPSS软件中的"广义线性混合模块" |
| ②将学校,班级,学生编号逐次拖入"主体(subjects)"区域["数据结构(data structure)"选项] | 指定数据层次结构 |
| ③"目标(target)":选择年末考试成绩,连接函数选择"线性模型(linear model)"["字段和效应(fields & effects)"选项] | 指定结局变量和连接函数 |
| ④"固定效应(fixed effects)":将学校位置、学校类型、教学方法、班级学生人数、性别、是否减免午餐以及年初成绩拖入"主(main)"区域["字段和效应(fields & effects)"选项] | 指定固定效应 |
| ⑤"随机效应(random effects)":默认拟合学校和班级两个层次水平的随机效应 | 指定随机效应 |
| ⑥"构建选项(build option)":默认即可→"运行(run)" | 指定结局变量参考类别,最大迭代次数,置信区间等 |
本模型输出结果包括:(1)模型摘要,包括设定的连接函数、残差概率分布和拟合信息标准等;(2)数据结构;(3)模型预测值和实际值的比较;(4)固定效应的估计值,默认以图形的方式给出结果,如需具体结果,可将"样式"框下拉切换为"表";(5)固定效应的系数估计和检验结果;(6)协方差矩阵;(7)协方差参数和随机效应估计值的结果;(8)拟合模型的设定摘要。固定效应和随机效应参数估计结果及解释同案例1和2,故此处不赘述。表8为整合后的结果,残差被分解到学校和班级水平后,仍有统计学意义,学校水平组内相关系数(intra-class correlation coefficent,ICC)即组间方差与总方差之比[12],ICC= ×100%=52.4%,班级水平的组内相关系数ICC=
×100%=52.4%,班级水平的组内相关系数ICC= ×100%-23.7%,分别表示学校水平和班级水平组内成绩的相似程度,表明学生年末成绩在学校和班级水平有聚集性,即数据有层次结构,采用混合模型更为合适,结果表明新教学方法较常规教学方法更好地提高成绩(P<0.001)。
×100%-23.7%,分别表示学校水平和班级水平组内成绩的相似程度,表明学生年末成绩在学校和班级水平有聚集性,即数据有层次结构,采用混合模型更为合适,结果表明新教学方法较常规教学方法更好地提高成绩(P<0.001)。
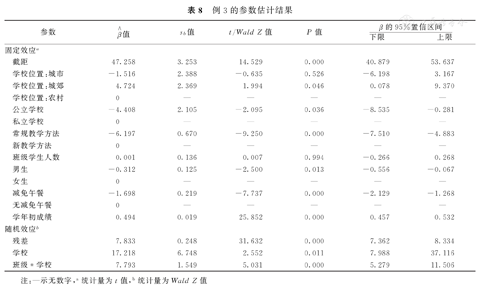
例3的参数估计结果
例3的参数估计结果
| 参数 |  值 值 | sb值 | t/Wald Z值 | P值 | β的95%置信区间 | ||
|---|---|---|---|---|---|---|---|
| 下限 | 上限 | ||||||
| 固定效应a | |||||||
| 截距 | 47.258 | 3.253 | 14.529 | 0.000 | 40.879 | 53.637 | |
| 学校位置:城市 | -1.516 | 2.388 | -0.635 | 0.526 | -6.198 | 3.167 | |
| 学校位置:城郊 | 4.724 | 2.369 | 1.994 | 0.046 | 0.078 | 9.370 | |
| 学校位置:农村 | 0 | — | — | — | — | — | |
| 公立学校 | -4.408 | 2.105 | -2.095 | 0.036 | -8.535 | -0.281 | |
| 私立学校 | 0 | — | — | — | — | — | |
| 常规教学方法 | -6.197 | 0.670 | -9.250 | 0.000 | -7.510 | -4.883 | |
| 新教学方法 | 0 | — | — | — | — | — | |
| 班级学生人数 | 0.001 | 0.136 | 0.007 | 0.994 | -0.266 | 0.268 | |
| 男生 | -0.312 | 0.125 | -2.500 | 0.013 | -0.556 | -0.067 | |
| 女生 | 0 | — | — | — | — | — | |
| 减免午餐 | -1.698 | 0.219 | -7.737 | 0.000 | -2.129 | -1.268 | |
| 无减免午餐 | 0 | — | — | — | — | — | |
| 学年初成绩 | 0.494 | 0.019 | 25.852 | 0.000 | 0.457 | 0.532 | |
| 随机效应b | |||||||
| 残差 | 7.833 | 0.248 | 31.632 | 0.000 | 7.362 | 8.334 | |
| 学校 | 17.218 | 6.748 | 2.552 | 0.011 | 7.988 | 37.116 | |
| 班级*学校 | 7.793 | 1.549 | 5.031 | 0.000 | 5.279 | 11.506 | |
注:—示无数字,a统计量为t值,b统计量为Wald Z值
所有作者均声明不存在利益冲突

























