
本文旨在对医学期刊统计报告要求中的条目进行详述与解读,为提高医学论文的统计报告质量提供参考。本文基于国际医学期刊编辑委员会(ICMJE)、提高健康研究质量与透明度协作网(EQUATOR)、中华医学杂志编辑部等发布的医学研究报告规范,从研究设计、统计分析与结果报告3个方面对统计学相关条目进行归纳,并结合已发表的医学论文进行案例解读。需要注意的是,英文医学期刊普遍参考ICMJE提出的"医学期刊学术著作实施、报告、编辑和发表建议"及EQUATOR协作网发布的针对多种研究设计类型的报告声明等规范性文件,对于医学研究的统计报告有详细规定;中文医学期刊通常采用编辑部自行刊发的对统计学报告的要求,虽然对统计分析的格式和内容有具体说明,但并不充分,建议根据国际规范完善现行的统计报告要求。本文对医学期刊统计报告要求的相关条目进行归纳与实例解读,将帮助研究者了解医学研究的统计报告要求,从而切实提高医学论文的统计报告质量。


版权归中华医学会所有。
未经授权,不得转载、摘编本刊文章,不得使用本刊的版式设计。
除非特别声明,本刊刊出的所有文章不代表中华医学会和本刊编委会的观点。
统计学设计、分析与表达的完整性与准确性会影响读者对临床研究结果真实性的判断。合理的统计设计、正确的统计分析与解读、规范的统计报告不仅是保证研究质量和数据真实性的前提,更是提高研究透明度和可重复性的重要保障。因此,生物医学期刊普遍在稿约中提出了针对研究统计事项的报告规范。这些规范一方面可以提示作者展示重要的研究信息,以便读者快速、全面了解研究的核心内容,另一方面可以帮助编辑和审稿人正确判断研究质量,做出刊发决定和评论[1]。
目前大多数期刊推荐参考国际医学期刊编辑委员会(International Committee of Medical Journal Editors,ICMJE)发布的"医学期刊学术著作实施、报告、编辑和发表建议"(Recommendations for the conduct,reporting,editing,and publication of scholarly work in medical journals)[2],对学术论文中研究方法和研究结果相关的统计事项制定了一般规范。近年来,为针对不同研究领域中可能涉及的关键细节给予更进一步的要求,如随机对照试验的随机化分配、病例对照研究的混杂因素控制等,提高健康研究质量与透明度协作网(Enhancing the QUAlity and Transparency of Health Research,the EQUATOR network)[3]整理并发布了适用于试验性研究的"临床试验报告统一标准"(CONsolidated Standards of Reporting Trials,the CONSORT statement)[4],适用于观察性研究的"增强流行病学中观察性研究的报告规范"(STrengthening the Reporting of OBservational studies in Epidemiology,the STROBE statement)[5],以及适用于其他研究设计类型的诸多报告规范。Liu等[6]曾对国际主流医学期刊(影响因子≥10)对统计事项的要求进行分析,发现大多数期刊在作者投稿指南中推荐使用上述报告规范。
然而,由于上述医学研究报告规范涵盖内容丰富,无法兼顾统计部分的详细要求,自20世纪80年代起,针对医学论文统计报告的指南相继问世。1988年,"医学期刊论文的统计报告指南:详述与解读"(Guidelines for statistical reporting in articles for medical journals:Amplifications and explanations)[7]首次从统计学角度提出了介绍统计方法、表达统计结果的建议。此后,其他医学期刊基于以上指南进行了修订与扩展[8,9],Lang和Altman[10]在此基础上整理并发布了"发表文献中的统计分析与方法学指南"(Statistical Analyses and Methods in the Published Literature,the SAMPL guideline)。尽管如此,一些医学期刊,如新英格兰医学杂志(New England Journal of Medicine,NEJM),也会根据自身需求有针对性的提出具体的统计报告要求[11]。
对于我国主办的医学期刊而言,英文期刊如中华医学杂志(英文版)[Chinese Medical Journal,CMJ (Engl)],其统计报告规范采用了ICMJE建议,并予以适当扩充[12];而中文期刊如中华医学杂志(中文版)、中华流行病学杂志等,则仍采用编辑部自行刊发的对统计学方法的要求[13,14],尚未普遍采用国际上已有的医学研究报告规范。
针对以上医学期刊的统计报告现状,本文对比了ICMJE建议、CONSORT声明、STROBE声明、统计报告指南(1988年)、SAMPL指南,以及NEJM、CMJ(Engl)、中华医学杂志、中华流行病学杂志等医学期刊的稿约中有关统计部分的要求,并将其中普遍涉及的统计事项进行总结,归纳为研究设计、统计分析与结果报告3部分,见表1。在此基础上,本文结合已发表的研究论文,从研究设计、统计分析与结果报告3方面涉及的统计学问题入手,进行逐条解读,以阐明医学论文应达到的统计报告要求。
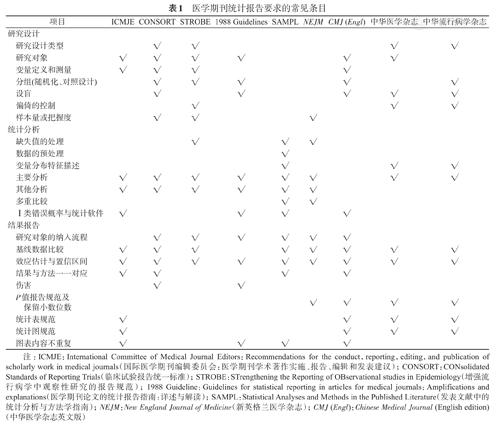
医学期刊统计报告要求的常见条目
医学期刊统计报告要求的常见条目
| 项目 | ICMJE | CONSORT | STROBE | 1988 Guidelines | SAMPL | NEJM | CMJ (Engl) | 中华医学杂志 | 中华流行病学杂志 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 研究设计 | ||||||||||
| 研究设计类型 | √ | √ | √ | √ | ||||||
| 研究对象 | √ | √ | √ | √ | √ | √ | ||||
| 变量定义和测量 | √ | √ | √ | √ | ||||||
| 分组(随机化、对照设计) | √ | √ | √ | √ | √ | |||||
| 设盲 | √ | √ | √ | √ | √ | |||||
| 偏倚的控制 | √ | √ | √ | |||||||
| 样本量或把握度 | √ | √ | √ | |||||||
| 统计分析 | ||||||||||
| 缺失值的处理 | √ | √ | √ | |||||||
| 数据的预处理 | √ | |||||||||
| 变量分布特征描述 | √ | √ | √ | |||||||
| 主要分析 | √ | √ | √ | √ | √ | √ | √ | √ | ||
| 其他分析 | √ | √ | √ | √ | √ | √ | ||||
| 多重比较 | √ | √ | ||||||||
| Ⅰ类错误概率与统计软件 | √ | √ | √ | √ | ||||||
| 结果报告 | ||||||||||
| 研究对象的纳入流程 | √ | √ | √ | √ | √ | √ | ||||
| 基线数据比较 | √ | √ | √ | √ | √ | √ | √ | √ | ||
| 效应估计与置信区间 | √ | √ | √ | √ | √ | √ | √ | √ | √ | |
| 结果与方法一一对应 | √ | √ | √ | √ | ||||||
| 伤害 | √ | √ | ||||||||
| P值报告规范及保留小数位数 | √ | √ | √ | √ | ||||||
| 统计表规范 | √ | √ | √ | √ | ||||||
| 统计图规范 | √ | √ | √ | √ | ||||||
| 图表内容不重复 | √ | √ | √ | √ | ||||||
注:ICMJE:International Committee of Medical Journal Editors:Recommendations for the conduct,reporting,editing,and publication of scholarly work in medical journals(国际医学期刊编辑委员会:医学期刊学术著作实施、报告、编辑和发表建议);CONSORT:CONsolidated Standards of Reporting Trials(临床试验报告统一标准);STROBE:STrengthening the Reporting of OBservational studies in Epidemiology(增强流行病学中观察性研究的报告规范);1988 Guideline:Guidelines for statistical reporting in articles for medical journals:Amplifications and explanations(医学期刊论文的统计报告指南:详述与解读);SAMPL:Statistical Analyses and Methods in the Published Literature(发表文献中的统计分析与方法学指南);NEJM:New England Journal of Medicine(新英格兰医学杂志);CMJ (Engl):Chinese Medical Journal (English edition)(中华医学杂志英文版)
(1)研究设计类型:医学论文应详细描述研究设计类型。对于试验性研究,CONSORT声明要求报告试验的具体分组特征(平行对照、析因设计或交叉设计等),各组间样本量分配比,以及试验开始后方法上的重要改变及原因[4]。例如,一篇有关围术期瑞舒伐他汀对窦性心律患者心肌损伤和术后房颤影响的研究论文(瑞舒伐他汀试验),即在研究设计部分,表明了该研究为一项"双盲、随机、安慰剂对照试验"(double-blind,randomized,placebo-controlled trial),分配比为1∶1;论文还在附件中提供了该研究的原始方案和统计分析计划,最终方案和统计分析计划,以及包含变更内容和日期的修订表[15]。
对于观察性研究,STROBE声明要求在方法学部分指出研究设计类型。队列研究应描述不同分组的人群及其暴露状态,病例对照研究应描述病例和对照组成及其源人群,横断面研究则应报告人群信息和调查的时间点[5]。
(2)研究对象:医学论文应报告研究对象的源人群(机构、地点、时间等)、抽样方法、选择标准和代表性等信息。例如,一篇基于中国慢性病前瞻性研究(China Kadoorie Biobank,CKB)发表的研究论文,详细描述了研究对象来源,包括:①源人群:2004年6月至2008年7月间,中国10个地区(5个城市和5个农村)的社区人群;②抽样方法:分层(城市或农村)、整群(所有符合选择标准的社区人群)、目标抽样(考虑地区的经济发展水平和人群的稳定性);③选择标准:35~74岁非残疾的常住居民,应答且签署知情同意书;④代表性考虑:研究地区涵盖了广泛的风险暴露和疾病模式,同时可以保证死亡和疾病登记的准确性和完整性,并具有收集必要研究数据的能力[16]。
(3)变量定义和测量:医学论文应充分描述主要变量的定义、数据来源及测量方法。试验性研究应详细报告各组的干预措施,包括干预内容,何时、如何实施;结局指标应明确区分主要和次要结局指标,以及具体的测量方法,包括何时、如何测量[4]。例如,在瑞舒伐他汀试验中,试验组和对照组的干预分别为:最早从术前8 d开始,至术后5 d结束,服用剂量为20 mg的瑞舒伐他汀或安慰剂片,每日1次;主要结局指标为:术后房颤(通过术后5 d连续Holter心电图监测)和围术期心肌损伤(根据术后6、24、48和120 h血样中的肌钙蛋白Ⅰ释放曲线下面积评估),次要结局指标包括院内心血管事件和死亡、ICU持续时间和住院时间等[15]。
观察性研究则应报告暴露因素、健康结局、潜在混杂因素和效应修正因子等变量的定义和测量标准,并说明其定义和测量标准的组间可比性[5]。例如,在CKB研究中,暴露因素为过去12个月内的习惯性水果摄入频率;健康结局为随访期首次发生的心血管死亡(ICD-10:I00~I25、I27~I88、I95~I99)、主要冠状动脉事件[包括致死性缺血性心脏病(ICD-10:I20~I25)及非致死性心梗(ICD-10:I21)]、出血性卒中(ICD-10:I61)、缺血性卒中(ICD-10:I63)、其他缺血性心脏病(非主要冠状动脉事件的缺血性心脏病)和其他脑血管病(ICD-10:I60、I62、I64~I69),ICD-10由不了解参与者基线特征的编码员编码;混杂因素为社会人口学特征、吸烟、饮酒、膳食、体力活动等;以上变量均由接受过培训的调查员通过问卷收集,以保证健康结局和混杂因素的测量在暴露组间保持一致[16]。
(4)分组:医学论文应对研究分组的合理性进行充分说明。试验性研究应详细描述随机化分组的过程,包括随机分配序列的产生方法、随机化类型(区组随机、整群随机等)、分配隐藏措施、以及负责上述过程的实施者[4]。例如,瑞舒伐他汀试验在附录中详细描述了随机化的过程,包括由某制药公司制造与瑞舒伐他汀相匹配的安慰剂片并包装活性剂和安慰剂,由某医院内不参加试验的人员提供随机表并标记治疗包(随机抽检了52个治疗包,发现标签与内容物均可对应),通过混合随机化的方法来增强分配隐藏,同时介绍了混合随机化方法的操作流程[15]。
至于观察性研究,病例对照研究应详细描述病例及对照的诊断信息,避免错分偏倚;队列研究则应详细描述暴露分组的方法与依据[5]。例如,CKB研究按水果摄入频率将研究对象划分为:每天、4~6 d/周、1~3 d/周、每月、极少或从不,共计5个不同的暴露水平组[16]。
(5)设盲:为控制信息偏倚,提高原始研究数据的准确性,无论在试验性研究还是观察性研究中,设盲都是十分必要的。因此,医学论文应对研究的设盲方法进行说明,包括设盲的对象、设盲的具体措施、以及设盲的实施者[4]。例如,一篇有关噻托溴铵对COPD早期干预的研究论文(噻托溴铵试验性研究),即采用双盲的措施,避免研究者和受试者在试验中提前了解自己的用药[17]。该试验由某药物研发公司生成盲底、封存并签字;盲底一式两份,由该公司和某医院共同保存;研究还准备了用于紧急揭盲的信封,留存于相关研究机构中[17]。而CKB(观察性研究)则设置了独立的事件评审委员会,对研究对象的结局事件进行ICD-10编码,并将研究对象的分组信息对其设盲,以减少可能的信息偏倚[16]。
(6)偏倚的控制:偏倚是影响研究真实性的主要问题,医学论文应报告控制偏倚的措施。试验性研究需要从是否随机分组、随机分组是否充分、是否设盲、是否采用中心读片、基线是否可比、随机分组后是否有治疗方案偏离、是否有失访等方面来报告控制偏倚的方法。观察性研究则应着重报告控制测量偏倚和信息偏倚的方法,包括培训调查员、使用标准测量方法、通过多种来源确定终点事件等。
(7)样本量或把握度:样本量是指在特定研究假设下,可以获得预期研究结果的最低样本数量需求;而把握度是指如果研究假设成立,即组间差异真实存在时,通过样本能够正确检出该差异的概率。医学期刊应在报告样本量计算过程中清晰地体现研究假设,同时明确统计推断的检验水准与方向(单/双侧),以及预期的把握度。例如,噻托溴铵试验假设噻托溴铵组与安慰剂组在24个月的第一秒用力呼气量差值为100 ml,标准差为350 ml,此时,在双侧5%的显著性水平下,纳入400对研究对象,可以有90%的把握度检测到两组的差异(考虑35%的预期脱失率)[17]。
(1)缺失值的处理:缺失值是人群研究中不可避免的问题,其处理方式的差异可能在不同程度上引入偏倚,因此,详细报告数据清理过程中缺失值的处理方法有助于读者对潜在偏倚风险进行评价。例如,瑞舒伐他汀试验在统计分析部分详细说明了缺失值的填补策略,包括:将二分类结局中的缺失值视为未发生事件;将生物标志物和心电图测量中的缺失值进行多重填补(multiple imputation);为了证明缺失值处理的合理性和填补结果的稳定性,研究还比较了多重填补与完整数据(complete-case)分析的结果[15]。
(2)数据的预处理:实施统计分析之前往往需要将原始数据进行预处理,如:对连续变量进行函数转换使其更接近正态分布,基于原始数据构建衍生变量,将连续变量拆分为分类变量或将分类变量的不同类别进行合并等[10]。医学论文应报告处理原始数据的方法及依据,瑞舒伐他汀试验即在统计分析部分描述了对血液生物标志物的对数转换[15]。
(3)变量分布特征描述:确定统计分析使用的变量,并针对每一个变量的分布特征进行描述,是决定研究选用何种统计分析方法的基础。医学期刊虽然普遍对此提出要求,但作者往往套用常用方法,如:连续变量符合正态分布时,采用均数(标准差)描述,否则采用中位数(四分位间距)描述;分类变量采用频数(百分比)描述等。事实上,应根据研究设计类型、统计分析目的和数据特征选择恰当的描述方法[13,14]。例如,CKB选择采用年龄、性别和地区校正的均值和率来描述人群分布特征,而非简单的报告连续变量的均数和分类变量的构成比[16]。
(4)主要分析(primary analysis):指针对研究结局的统计分析,是研究论文的核心证据。因此,医学论文应详细描述主要分析的实施过程和适用性。在试验性研究中,应明确统计分析数据集、试验效应指标、相对或绝对风险及其置信区间的计算方法、以及假设检验的方法。例如,瑞舒伐他汀试验采用意向性分析(intention to treat)数据集,通过计算OR值及其95%CI来评价术后房颤发生风险在试验组与对照组间的差异,置信区间包含1说明研究结果不拒绝原假设,即两组的术后房颤发生风险相等;考虑到重复测量的需要,采用协方差分析比较两组术后6~120 h肌钙蛋白Ⅰ释放曲线下面积的对数,并计算其均值的绝对差异及其95%CI来评价围术期心肌损伤情况在试验组与对照组间的差异,置信区间包含0说明研究结果不拒绝原假设,即两组的围术期心肌损伤情况相同[15]。
在观察性研究中,通常采用多因素统计模型来控制混杂,此时应明确定义因变量、自变量及潜在的混杂变量或效应修正因子,描述变量转换的方法和变量筛选的过程,并预先说明论文报告哪一种统计模型的结果。如果采用读者并不熟悉的统计分析方法,还应详细介绍该统计分析方法的原理。例如,CKB采用Cox比例风险回归模型分析水果摄入与心血管事件之间的关联,因变量为心血管事件,包括心血管死亡、主要冠状动脉事件、出血性卒中、缺血性卒中、其他缺血性心脏病和其他脑血管病;自变量为水果摄入频率,即每天、4~6 d/周、1~3 d/周、每月、极少或从不;分层变量为年龄、性别和地区;同时模型调整了基线的混杂变量;为了帮助多个暴露类别之间的比较,研究采用浮动绝对风险的方法(floating-absolute-risk method)估计危险比的变异程度,并与传统的不浮动绝对风险的方法进行比较[16]。
(5)其他分析:如果研究在主要分析之外,还进行了其他辅助分析(ancillary analysis),如敏感性分析(sensitivity analysis)或亚组分析(subgroup analysis),应在统计分析部分给予充分说明。如果是事后分析(post-hoc analysis),应考虑潜在的Ⅰ类错误膨胀问题[11]。例如,瑞舒伐他汀试验在主要分析的基础上,根据基线年龄(≤60岁或>60岁)、性别、他汀用药史(是或否)等变量分亚组比较主要结局指标在试验组与对照组间的差异。但是,由于该亚组分析在研究设计时已预先设定(pre-specify),因此无需对显著性水平进行调整[15]。
(6)多重比较:除了常规使用的统计分析方法外,作者还应特别注意多重比较的问题。例如,瑞舒伐他汀试验设置了两个平行的主要结局指标:术后房颤和围术期心肌损伤,原则上应调整显著性水平以控制总体Ⅰ类错误概率[11]。然而,由于研究假设两个主要结局指标同时达到组间差异有统计学意义才算试验阳性,且在估算样本量时已对此给予了充分考虑,因此无需考虑多重检验的问题(without allowance for multiple testing)[15]。
(7)Ⅰ类错误概率与统计软件:医学论文应对统计检验的Ⅰ类错误概率(单/双侧)及统计软件进行说明。例如,两部分数据分别采用SAS 9.3和Stata 13.0软件进行分析,所有检测均为双侧检验,P<0.05为差异有统计学意义[18]。
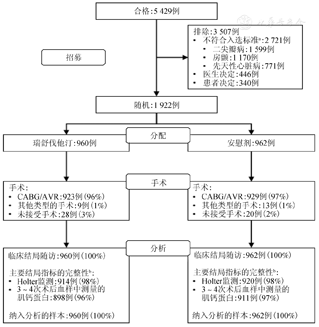
(1)研究对象的纳入流程:医学期刊推荐使用研究对象流程图来描述研究对象的纳入流程、研究实施过程中的失访或无应答、以及最终的统计分析数据集等信息,见图1。研究对象流程图的展示可以为研究对象是否存在选择偏倚、研究结果的可外推范围等提供重要证据。
(2)基线数据比较:医学期刊通常要求分组报告基线变量的分布特征,但在组间比较时可以不做假设检验,不标注P值,见表2。因为,在大样本研究中,绝对差异的微小改变都可能造成统计学显著,而该差异本身并不一定具有临床意义。另一方面,在样本量较小的随机对照试验中,即便采用了严格的随机分组策略,仍会有个别变量无法达到组间可比,此时,如果预先对基线数据进行组间比较,作者可能会选择性不报告组间差异有统计学意义的变量,而导致选择性报告偏倚。
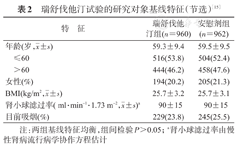
瑞舒伐他汀试验的研究对象基线特征(节选)[15]
瑞舒伐他汀试验的研究对象基线特征(节选)[15]
| 特征 | 瑞舒伐他汀组(n=960) | 安慰剂组(n=962) | |
|---|---|---|---|
年龄(岁, ±s) ±s) | 59.3±9.4 | 59.5±9.5 | |
| ≤60 | 516(53.8) | 504(52.4) | |
| >60 | 444(46.2) | 458(47.6) | |
| 女性(%) | 194(20.2) | 205(21.3) | |
BMI(kg/m2, ±s) ±s) | 25.7±3.2 | 25.7±3.1 | |
肾小球滤过率(ml·min-1·1.73 m-2, ±s)a ±s)a | 90±15 | 90±15 | |
| 目前吸烟(%) | 229(23.8) | 245(25.5) | |
注:两组基线特征均衡,组间检验P>0.05;a肾小球滤过率由慢性肾病流行病学协作方程估计
(3)效应估计与置信区间:医学论文在报告统计结果时不应仅依赖于P值,还应给出量化的效应估计结果,同时评价其测量误差或不确定性,如报告95%CI(如有必要,可根据显著性水平对置信系数进行调整[11])。因为P值无法反映关于效应大小和估计精度的重要信息,只能说明统计学意义,而损失对临床意义的表达。SAMPL指南建议研究者给出临床意义的最小界值,以帮助读者根据点估计及置信区间判断研究的临床意义[10]。中华流行病学杂志则提出,当P值小于Ⅰ类错误概率时,应说"组间差异有统计学意义",而不应说"组间有显著性差异"[14]。例如,CKB在评价研究因素对结局的发生风险时,报告了危险比及其95%CI[16]。
(4)结果与方法一一对应:医学论文应保证研究结果与方法一一对应,如:在方法中介绍了基线的统计描述与组间比较的具体方法,应在结果中对基线数据进行相应的描述与比较;在方法中说明了研究的主要分析方法,应在结果中对主要结局指标的估计或假设检验结果进行报告;在方法中提出了其他分析,包括敏感性分析、亚组分析等,应在结果中罗列出相应内容。例如,瑞舒伐他汀试验在方法部分说明研究将对主要结局指标、次要结局指标分别进行组间比较,并对主要结局指标进行亚组分析;在结果部分则依次报告了相应结果[15]。
(5)伤害:需要注意的是,无论是试验性研究还是观察性研究,都有可能存在伤害研究对象的风险。医学论文应如实报告研究过程中发生的伤害[4]。例如,噻托溴铵试验报告了试验组与对照组的不良事件发生情况:除了轻度不良事件(如口咽不适)外,其他不良事件、严重不良事件和死亡发生率的组间差异均无统计学意义[17]。
(6)P值的报告规范及保留小数位数:不同医学期刊对P值的报告规范有不同要求。例如,NEJM规定,除非研究设计需要进行单侧检验,如非劣效性试验,其他报告的P值均应为双侧。P值大于0.01应报告小数点后两位;P值在0.01到0.001之间应报告小数点后三位;P值小于0.001应报告为P<0.001。在分层分析中,只需报告层间比较差异有统计学意义的P值,而不需报告所有层间两两比较的P值[11]。CMJ(Engl)规定,应使用大写斜体,并报告P值的精确值(如果P值在0.001~0.05之间时)[12]。中华医学杂志规定,应尽可能给出具体的P值[13]。中华流行病学杂志规定,应给出P值的实际数值,并保留3位小数。在使用不等式表示P值时,选用P>0.05、P<0.05和P<0.01即可满足需求,无须细分P<0.001或P<0.000 1[14]。可以看出,目前医学期刊对P值的报告尚无统一规范,导致一些研究仅给出P值与显著性水平之间的不等关系,而不体现量化的数值(如P>0.05);一些研究则盲目追求P值的精度,而保留不必要的小数位数(如P=0.035 7)。
(7)统计表规范:统计表可以简明、高效地展示研究的关键信息。ICMJE对统计表的要求包括:依照正文的引用顺序连续编码,并确保每个表都在正文中被引用;设置简短清晰的表标题,使读者可以直接理解表中内容而无需阅读上下文;设置简短清晰的纵标目与横标目,并在脚注中解释标目涉及的细节问题;在脚注中解释所有表中的非标准缩写,同时明确变异特征,如标准差或标准误;如果表中用到其他来源的已发表或未发表的数据,应获取许可并充分引用[2],见表2。
(8)统计图规范:统计表用于展示数据的精确数值,而统计图则提供对数据的全面评估[10]。ICMJE对统计图的要求包括:依照正文的引用顺序连续编码,并确保每张图都在正文中被引用;如果图片已经发表,应获取许可并充分引用;如果存在符号、箭头、数字或字母用于标记图片,需在图例中逐一解释[2],见图1。不同杂志还会对图片的格式和大小进行进一步要求。统计图表达方式的创新有助于读者快速掌握研究的核心结果。
(9)图表内容不重复:医学论文的图表内容不应重复,且不应在文中复述图表中的所有数据;应仅强调或总结最重要的结果。例如,瑞舒伐他汀试验在结果部分依次用图表展示了基线(表1)、主要结局指标及亚组分析(图1)、共同主要结局指标(图2)和次要结局指标(表2)的相关内容[15]。
本文从研究设计、统计分析、结果报告3方面涉及的统计学问题入手,对医学期刊的统计报告条目及内容进行归纳,并借助试验性研究和观察性研究论文,对其进行逐条解读,以阐明医学论文统计报告应达到的基本要求。本文发现,英文医学期刊普遍参考ICMJE提出的"医学期刊学术著作实施、报告、编辑和发表建议"[2]及EQUATOR协作网发布的针对多种研究设计类型的报告声明[3]等规范性文件,对于医学研究的统计报告已有详细规定。而中文医学期刊通常采用编辑部自行刊发的对统计学方法的要求,虽然对统计分析的格式和内容有具体说明,但并不充分,建议根据国际规范完善现行的统计报告要求。需要注意的是,本文介绍的统计报告条目是不同研究设计类型均可能涉及的共性问题,当研究者在进行论文撰写时,应根据自身的研究设计类型、研究目的与学术期刊要求选择参考适用的条目,而非逐一报告。本文有望帮助研究者了解医学研究的统计报告要求,从而切实提高医学论文的统计报告质量。
所有作者均声明不存在利益冲突

























