
建立新型冠状病毒肺炎(COVID-19)患者转归为重症的预测模型,为早期、动态地监测患者转归提供更加全面、准确、及时的指标。
基于患者的入院检测指标和轻、重症分型,以及检测指标的动态改变(即入院后两次检测指标测量值差)等输入变量,使用XGBoost方法建立预测模型,评估患者在入院之后转归为重症的风险。然后将入选的患者从入院随访至出院,观察其病情转归情况,对模型预测结果进行验证。
在100例COVID-19患者的训练集中,筛选出具有较高评分的预测变量并建立模型,计算出预测变量取值的高风险范围:血氧饱和度<94%、外周血白细胞计数>8.0×109个、SBP变化<-2.5 mmHg(1 mmHg=0.133 kPa)、心率>90次/min、有多发小斑片影、年龄>30岁、心率变化<12.5次/min。训练集的模型预测结果的敏感率为61.7%,漏诊率为38.3%;使用模型对测试集进行预测的敏感性为75.0%,漏诊率为25.0%。
与传统的预测判断方法(即采用入院时第一次检测的指标和重症入选条件进行评估患者是否为轻、重症)相比,模型的预测考虑到了COVID-19患者的基线生理指标与病情变化指标,因此能够全面、准确地预测患者重症转归的风险,减少重症患者的漏诊率。


版权归中华医学会所有。
未经授权,不得转载、摘编本刊文章,不得使用本刊的版式设计。
除非特别声明,本刊刊出的所有文章不代表中华医学会和本刊编委会的观点。
2019年12月8日以来,湖北省武汉市连续报告了多例不明原因肺炎病例。2020年1月7日,中国CDC从患者的咽拭子样本中鉴定出一种新型冠状病毒。2020年2月8日国家卫生健康委员会将新型冠状病毒感染的肺炎命名为"新型冠状病毒肺炎",2月21日国家卫生健康委员会决定将"新型冠状病毒肺炎"英文名称修订为"COVID-19",与WHO命名保持一致,中文名称保持不变[1]。COVID-19是一种新发传染病,人群普遍缺乏免疫力,所以具有人群易感性。患者典型的症状为发热、咳嗽或腹泻等。病毒主要侵犯肺部,造成呼吸功能障碍,严重可导致患者死亡。有研究表明,截至2月10日,全国(湖北省除外)COVID-19病死率为0.88%,湖北省(武汉市除外)病死率为1.70%,武汉市病死率为4.05%[2]。WHO总干事于3月11日在日内瓦宣布,经过疫情评估后认为,COVID-19已构成"大流行病"[3]。全球多个国家暴发不同程度的疫情,截至3月23日,全球COVID-19确诊病例已经超过30万例[4]。我国成功的抗疫经验将会对世界各国战胜疫情产生积极影响,因此,相关研究有着重要的现实意义。随着疫情的发展,涉及的病例越来越多,且病情复杂多变,导致临床救治负担越来重。2020年2月3日晚,为落实"四集中"要求,解决床位问题,加快病房周转率,重、轻症分流机制形成。为确保确诊患者应收尽收,武汉市政府紧急决定在江汉区、武昌区、东西湖区建设速成式"方舱医院"用于收治COVID-19轻症患者[5]。方舱医院集隔离、监测、治疗等功能于一体,主要用于轻型患者的救治[6],也可及时鉴别重症转归患者并报送至定点医院救治。
早期研究发现重型、普通型和轻型患者的比例分别为25.5%、69.9%和4.5%,合并基础疾病的老年男性病死率更高;重型患者病死率高于普通型和轻型;诊断时间越晚(发病至诊断时间超过5 d),死亡风险越高[2]。因此,能够及时、准确地识别重症患者,开展针对性的治疗,有利于医疗资源的合理分配、避免资源浪费,更有利于降低重症患者的死亡率。这促使了全方位方舱支持平台的出现,既可以在临床上指导治疗与转诊,在患者多、医患比小的情况下,高效、快速地预测疾病转归结局,为广大医务人员提供重要参考;又可以为广大患者提供顺畅的医患沟通渠道和心理健康支持。对重症患者转归的传统预测方法是采用入院时第一次检测的指标和重症入选条件区分轻、重症,该法虽简便及时,但未能综合考虑患者特征及病情的动态变化。本研究建立重症患者转归的预测模型,利用COVID-19患者的临床及随访资料,评价重症患者的转归风险,为早期发现重症转归的患者提供便捷、准确、科学的依据。
武汉市方舱医院2020年1月27日至3月8日的病例,共有2个中心参与此项研究。纳入的人群为通过实时荧光RT-PCR检测新型冠状病毒核酸阳性或者血清新型冠状病毒特异性IgM抗体和IgG抗体检测阳性则确诊为COVID-19病例。重症病例入选的条件参考《新型冠状病毒肺炎诊疗方案(试行第六版)》[7](符合以下任意一条):血氧饱和度≤93%;呼吸频率≥30次/min;动脉血氧分压(PaO2)/吸氧浓度(FiO2)≤300 mmHg(1 mmHg=0.133 kPa)。本研究通过南京医科大学第一附属医院伦理委员会审查(审批文号:2020-SR-106)。
所有纳入病例入院检测的参数共有49个,包括人口统计学特征、生命体征、临床检验监测参数和CT参数、疾病和治疗特征、临床特征和病理变量(表1)。

训练集和测试集预测变量的比较
训练集和测试集预测变量的比较
| 变量 | 训练集 | 测试集 | P值a | |
|---|---|---|---|---|
| 基础信息 | ||||
| 年龄(岁)b | 45.58±13.19 | 46.12±12.26 | 0.82 | |
| 性别(男/女)c | 36/63 | 24/17 | 0.03 | |
| 吸烟c | 0/11 | 1/4 | 0.68 | |
| 病史c | ||||
| 心血管系统疾病 | 3/100 | 2/43 | 1.00 | |
| 呼吸系统疾病 | 0/100 | 1/43 | 0.67 | |
| 免疫系统疾病 | 0/100 | 0/43 | ||
| 内分泌系统疾病 | 3/100 | 1/43 | 1.00 | |
| 肿瘤 | 0/100 | 0/43 | ||
| 合并感染 | 30/100 | 14/43 | 0.97 | |
| 生命体征 | ||||
| 发热c | 78/100 | 33/43 | 1.00 | |
| 咳嗽c | 52/87 | 22/37 | 1.00 | |
| 心率(次/min)b | 87.40±12.95 | 89.95±17.76 | 0.34 | |
| SBP(mmHg)b | 124.95±15.95 | 126.86±17.80 | 0.53 | |
| DBP(mmHg)b | 79.70±9.38 | 82.26±11.96 | 0.17 | |
| 体温(℃)b | 36.78±0.73 | 36.68±0.56 | 0.43 | |
| 临床检验检测参数 | ||||
| 血氧饱和度(%)b | 96.48±2.35 | 97.14±1.42 | 0.09 | |
| 外周血白细胞计数(109/L)b | 5.28±1.85 | 5.94±2.94 | 0.19 | |
| 淋巴细胞计数(109/L)d | 0.86(0.59~1.31) | 0.78(0.52~1.29) | 0.40 | |
| 乳酸脱氢酶(U/L)b | 252.72±113.85 | 268.27±95.35 | 0.66 | |
| C-反应蛋白(mg/L)d | 13.83(11.50~20.23) | 34.33(0.50~43.44) | 0.33 | |
| 超敏C-反应蛋白(mg/L)d | 7.20(3.00~22.86) | 10.66(3.00~42.69) | 0.79 | |
| 血沉(mm/h)b | 31.96±19.74 | 31.91±15.90 | 0.99 | |
| D-二聚体(mg/L)d | 0.24(0.15~0.38) | 0.20(0.10~0.52) | 0.91 | |
| 肌钙蛋白(μg/L)b | 0.01±0.00 | 0.01±0.00 | 0.78 | |
| 降钙素(μg/L)d | 0.07(0.04~0.09) | 0.06(0.04~0.09) | 0.18 | |
| 谷丙转氨酶(U/L)b | 21.48±16.03 | 25.38±15.02 | 0.46 | |
| 谷草转氨酶(U/L)b | 27.70±16.83 | 29.86±12.55 | 0.67 | |
| CT参数c | ||||
| 肺多发小斑片影 | 52/100 | 25/43 | 0.83 | |
| 肺间质改变 | 29/100 | 16/43 | 0.61 | |
| 肺外带明显 | 6/100 | 3/43 | 1.00 | |
| 双肺多发玻璃影 | 51/100 | 27/43 | 0.58 | |
| 双肺多发浸润影 | 2/100 | 2/43 | 0.76 | |
| 肺实质改变 | 9/100 | 6/43 | 0.62 | |
| 指标变化d | ||||
| 心率变化(次/min) | -2.50(-13.00~8.00) | -4.00(-12.00~7.00) | 0.72 | |
| SBP变化(mmHg) | 0.00(-11.50~10.00) | 3.00(-15.50~15.75) | 0.82 | |
| DBP变化(mmHg) | -0.50(-7.00~6.00) | -1.50(-10.00~5.75) | 0.62 | |
| 体温变化(℃) | -0.10(-0.60~0.20) | -0.10(-0.60~0.15) | 0.89 | |
| 血氧饱和度变化(%) | 0.00(-2.00~1.00) | 0.00(-1.50~0.00) | 0.80 | |
| 外周血白细胞计数变化(109/L) | 1.00(-0.30~2.80) | 0.45(-0.35~1.95) | 0.25 | |
| 淋巴细胞计数变化(109/L) | 0.62(0.19~0.87) | 0.41(0.16~1.00) | 0.58 | |
| 乳酸脱氢酶变化(U/L) | -5.00(-29.65~17.25) | -11.90(-41.45~18.05) | 0.79 | |
| 超敏C-反应蛋白变化(mg/L) | -0.29(-4.42~25.28) | 0.18(-10.11~8.50) | 0.63 | |
| 血沉变化(mm/h) | -5.50(-11.00~2.00) | 2.00(-3.00~4.00) | 0.53 | |
| D-二聚体变化(mg/L) | 0.16(-0.55~0.40) | 0.42(0.38~0.45) | 0.29 | |
| 肌钙蛋白变化(μg/L) | 0.00(0.00~0.00) | 0.00(0.00~0.00) | 0.22 | |
| 降钙素变化(μg/L) | -0.02(-0.04~-0.01) | -0.02(-0.03~0.00) | 0.35 | |
| 谷丙转氨酶变化(U/L) | 4.70(0.68~19.33) | 3.80(-1.65~14.70) | 0.96 | |
| 谷草转氨酶变化(U/L) | -0.95(-10.33~3.93) | -2.60(-9.80~-1.15) | 0.33 | |
| 转归c | ||||
| 患者转归(重症/患者总数) | 22/100 | 8/43 | 0.65 | |
注:训练集中重症患者的比例为22.00%(22/100),测试集为18.60%(8/43);a数据差异检验采用成组t检验和构成比的χ2检验;b数据表示为 ±s;c数据为计数/总数;d数据为M(P25~P75)
±s;c数据为计数/总数;d数据为M(P25~P75)
XGBoost是一种机器学习技术[8],通过组装弱预测模型(通常是决策树)来构建预测模型。在训练过程中,以梯度增强的方式生成一系列决策树,即根据当前的决策树递进生成下一个决策树,以更好地预测结果[9]。经过训练,可得到由一系列决策树组成的风险预测系统。在应用过程中,输出预测风险是每个决策树的累计得分,表示为预测结果的概率。XGBoost有两个特别的优势。首先,XGBoost提供每个变量的重要度评分,代表了该变量在预测模型中的权重。其次,XGBoost算法可以通过为每个树节点中缺失的值添加默认方向来自动处理缺失数据,默认方向从训练数据中学习获得。当验证数据中存在缺失值时,将该实例分类为默认方向。而这个优势是其他机器学习方法和传统统计模型无法比拟的,因为这些模型不能够自动处理缺失值,在这些模型中,通常用平均值替代的方式填充缺失值[10]。
基于患者的入院检测指标和初步轻、重症分型,以及入院指标的动态改变(即入院后第二次测量值减去第一次测量值)等输入变量,建立预测模型,评估患者在入院之后患重症的风险,既考虑到患者基础指标(如初步轻、重症分型、生命体征和临床检测等),又包含有患者入院后的动态指标(如心率变化、血压变化和临床检测指标变化等)。入选的患者从入院随访至出院,观察其病情转归,对模型预测结果进行验证。
根据COVID-19诊断标准,本研究共纳入143例患者。随机抽取100例患者作为训练集,其余43例患者的数据作为测试集。针对49个变量,基于变量的高预测能力和广泛可获取性原则,结合受试者特征曲线(ROC)和数据缺损率筛选出用于疾病转归预测的候选变量,候选预测变量需满足以下条件:①AUC>0.6,②数据缺损率<50%。将初步筛选后的预测变量作为输入项,带入XGBoost中进行训练,将患者转归作为输出。将原始训练集数据(共100例)平均分成5组,将每个子集数据分别当作一次验证集,其余的4组子集数据作为训练集,会由此得到5个模型,用这5个模型最终的验证集的分类准确率的平均数作为五折交叉验证模型下的性能指标。在模型性能的评价指标中,除了准确率之外,临床上更为关注的指标是敏感度,即在金标准判断重症(阳性)人群中,检测出阳性的概率,这样能做到尽可能地避免重症患者的漏诊。采用传统方法作为对照,即采用入院时第一次检测的指标和重症入选条件进行评估患者是否为轻、重症,与XGBoost预测模型进行对比,以判断预测模型的优劣性。
根据入院时间将纳入的人群分为训练集和测试集,见表1。训练集总体数据的缺失率为32.02%,测试集为37.54%。身体测量指标变化信息见表2。
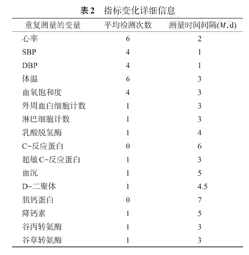
指标变化详细信息
指标变化详细信息
| 重复测量的变量 | 平均检测次数 | 测量时间间隔(M,d) |
|---|---|---|
| 心率 | 6 | 2 |
| SBP | 4 | 1 |
| DBP | 4 | 1 |
| 体温 | 6 | 3 |
| 血氧饱和度 | 4 | 3 |
| 外周血白细胞计数 | 1 | 3 |
| 淋巴细胞计数 | 1 | 3 |
| 乳酸脱氢酶 | 1 | 4 |
| C-反应蛋白 | 0 | 6 |
| 超敏C-反应蛋白 | 1 | 3 |
| 血沉 | 1 | 5 |
| D-二聚体 | 1 | 4.5 |
| 肌钙蛋白 | 0 | 7 |
| 降钙素 | 1 | 5 |
| 谷丙转氨酶 | 1 | 3 |
| 谷草转氨酶 | 1 | 3 |
初步利用ROC进行初步筛选,候选预测变量包括血氧饱和度、外周血白细胞计数、SBP变化、心率、心率变化、多发小斑片影、年龄和体温变化。预测变量的缺失率见表3。
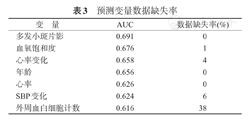
预测变量数据缺失率
预测变量数据缺失率
| 变量 | AUC | 数据缺失率(%) |
|---|---|---|
| 多发小斑片影 | 0.691 | 0 |
| 血氧饱和度 | 0.676 | 1 |
| 心率变化 | 0.658 | 4 |
| 年龄 | 0.656 | 0 |
| 心率 | 0.626 | 0 |
| SBP变化 | 0.624 | 6 |
| 外周血白细胞计数 | 0.616 | 38 |
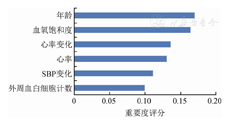
然后将XGBoost模型中所用的输入变量进行重要性评分(图1),最终入选的变量(按照重要性排序)为年龄、血氧饱和度、心率变化(入院后第二次测量值减去第一次测量值)、心率、SBP变化(入院后第二次测量值减去第一次测量值)、外周血白细胞计数。变量体温变化虽具有较高的预测能力,但与其他预测变量具有共线性或者较高的相关系数,所以未纳入模型。
根据训练集的数据将筛选出来的变量进行模型的构建(图2)。模型中预测变量高风险的范围,见表4。
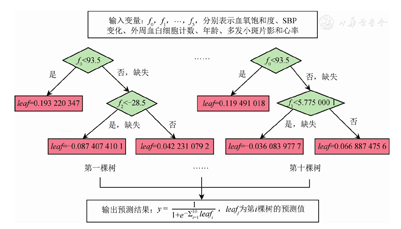

各变量定义及高风险值范围
各变量定义及高风险值范围
| 变量 | 定义 | 高风险范围 |
|---|---|---|
| 血氧饱和度(%) | 入院时第一次检测的数值 | <94 |
| 外周血白细胞计数(109/L) | 入院时第一次检测的数值 | >8.0 |
| SBP变化(mmHg) | 入院时第二次检测的数值减去第一次检测的数值的差值,两次检测间隔时间≥1 d | <-2.5 |
| 心率(次/min) | 入院时第一次检测的数值 | >90 |
| 多发小斑片影 | 入院时第一次检测的数值 | 是 |
| 年龄(岁) | 入院时第一次检测的数值 | >30 |
| 心率变化(次/min) | 入院时第二次检测的数值减去第一次检测的数值的差值,两次检测间隔时间≥1 d | <12.5 |
在训练集(n=100)中,使用传统方法(即采用入院时第一次检测的指标和重症入选条件进行评估患者是否为轻/重症)进行分类,可得到85.0%的预测准确率,31.8%的预测敏感性,即确诊的22例重症患者中只有7例被检测出来,漏诊率为68.2%。而使用模型预测方法的敏感率为61.7%,漏诊率为38.3%(表5)。
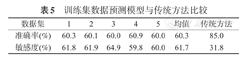
训练集数据预测模型与传统方法比较
训练集数据预测模型与传统方法比较
| 数据集 | 1 | 2 | 3 | 4 | 5 | 均值 | 传统方法 |
|---|---|---|---|---|---|---|---|
| 准确率(%) | 60.3 | 60.1 | 60.0 | 60.9 | 60.0 | 60.3 | 85.0 |
| 敏感度(%) | 61.8 | 61.9 | 64.9 | 59.8 | 60.0 | 61.7 | 31.8 |
除训练集和测试集外,对1位53岁的患者进行病情转归的预测,前期血氧饱和度为94%,外周血白细胞计数6.54×109/L,SBP下降26 mmHg,心率为104次/min,有多发小斑片影,经过模型预测,该患者转变为重症的可能性较大,而实际上,该患者最终也转为重症患者。
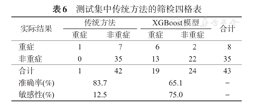
本研究采用机器学习算法,基于入院信息和指标动态变化,建立患者转归预测模型,可以为早期、动态地识别与监测重症患者提供重要的风险指标,与传统方法(即入院时第一次检测的指标和重症入选条件进行评估患者是否为轻重症)相比具有更高的准确性和敏感性。使用传统方法对训练集和测试集的数据进行病程转归的预测,发现在训练集的100例病例中,能够得到85.0%的预测准确率,31.8%的预测敏感性,即确诊的22例重症患者中只有7例被预测出来,漏诊率高达68.2%。在测试集中,其结果是在8例确诊的重症患者中,仅预测出1例重症患者,漏诊率高达87.5%,这极大地影响了对即将转归的危重患者的识别并可能耽误及时救治,导致病情的延误,提高了死亡率。
本研究借助人工智能等多种算法,最终选择使用XGBoost预测模型,筛选出6个变量:年龄、血氧饱和度、心率变化、心率、SBP变化、外周血白细胞计数。这6项指标的重要性从高到低排列,每项指标的权重也呈一定的递减趋势。已有研究显示,在重症死亡病例中,大多数为≥60岁患者,且患有基础性疾病,如高血压、心血管疾病和糖尿病等,这与我们模型预测变量的结果相符合[2]。从生物学角度来说肺炎患者通气受限造成缺氧,血氧饱和度下降,为保证组织供氧,引起心率代偿性加快;同时,发热状态下体液流失可能导致血容量减少,引发血压下降,此时回心血量减少,每搏输出量减少,为维持心输出量,也会引起心率代偿性加快。白细胞计数是临床常见的炎症反应指标,细菌性感染时通常会升高,病毒性感染时常表现为不升高或下降[11]。感染新型冠状病毒时白细胞计数的上升,可能是由肺部并发细菌性感染或缺氧引起的炎症反应导致[12]。肺功能随年龄增长和炎症程度加重而下降[13]。进行模型构建后,得到训练集模型预测结果的敏感率为61.7%,漏诊率仅为38.3%。相较于传统的预测方法,构建模型的预测大大提高了对病情转归预测的敏感性,更能够及时准确地发现病例,避免疫情期间医疗资源的浪费,并可及时采取一系列针对性的措施。
综上所述,使用XGBoost预测模型对COVID-19病情转归进行预测,能够帮助医务人员方便、快捷、准确地评估患者的病情变化,从而为早期、动态地发现COVID-19重症转归提供参考。但本研究的样本量有限,对于结局的预测未能达到绝对的理想范围,而且由于XGBoost有许多超参数,因此它的优化可能是一项非常艰巨的任务[14]。不过模型本身也是不断迭代、不断进步的,随着新的数据加入,分析结果将会越来越精确。
所有作者均声明不存在利益冲突

























