
版权归中华医学会所有。
未经授权,不得转载、摘编本刊文章,不得使用本刊的版式设计。
除非特别声明,本刊刊出的所有文章不代表中华医学会和本刊编委会的观点。
Logistic回归分析在医学研究中十分常见,主要用于研究一个分类结局与多个影响因素之间的关系。在实际应用中,logistic回归有很多需要注意的问题,如因变量与自变量的线性关系、自变量之间的共线性、异常值等[1,2]。这些是保证logistic回归模型正确应用的必要条件,然而对临床医生尤其是基层医生而言,这些专业问题通常需要统计学家的协助,logistic回归分析逻辑则是基层医生更值得关注的问题。现通过分析医学论文中logistic回归的应用案例,对其分析中的常见逻辑错误进行总结和辨析,为基层医生正确使用logistic回归提供借鉴。
Logistic回归与线性回归类似,只是线性回归的结局要求是连续型变量,而logistic回归的结局则为分类变量。分类变量既可以是二分类(如发病和不发病、达标和不达标、复发和不复发等),也可以是无序多分类变量(如根据新生儿体重分为正常儿、巨大儿、低体重儿)和有序多分类变量(如根据治疗效果分为有效、好转、无效)。
在医学研究中,logistic回归常应用于以下情形:(1)初步探索某疾病(或其他结局)的危险因素,如探索影响居民签约现况(是或否)的因素有哪些[3];(2)校正可能的混杂因素后,验证某结局与感兴趣的研究因素之间的关联,如为了分析肌少症对老年慢性心力衰竭患者活动能力下降的影响,对年龄、性别、纽约心脏病协会(NYHA)分级、左心室射血分数等混杂因素进行校正[4];(3)基于某些危险因素,预测某疾病(或其他结局)发生的风险,如评价预后营养指数与高龄胃癌患者临床手术风险及预后的关系[5]。
现主要总结并讨论logistic回归分析中的以下几类问题。
例1.某研究分析癫痫患者癫痫知识水平的可能影响因素,该研究采用某癫痫知识问卷进行评分,最终按评分结果自行根据第25、50、75百分位数将评分划分为4类,将其作为有序分类变量,采用累积比数logit模型进行分析。该研究同时还根据第75百分位数将结局分为两类,采用二分类logistic回归再次进行分析。
案例分析:该研究的主要问题为是否有必要将问卷评分划分为分类变量。对于连续变量结局,如无特殊必要,通常尽量基于原始数据形式进行分析,这样可以最大限度保留变量信息。本文中作者提到将评分划分为多分类结局的理由是评分不满足正态性。这一理由并不充分,因为对于连续变量,即使不满足正态分布,也有很多替代方法,如中位数回归、对数变换等。仅因为结局不满足正态分布便将其转换为分类变量,不仅损失了信息,而且简单根据四分位数划分为4类,也缺乏合理的依据。
建议:对于连续变量结局,除非有专业上的考虑(如实际应用或解释更方便等),而且有较为合理的分割点,否则不建议将连续变量转换为分类变量。因为这种转换方式不仅会导致信息损失,而且可能会引发"分割点是否合理"这一问题。如果基于专业考虑,确实需将连续变量划分为分类变量,建议首先根据专业知识划分;如果没有合理的专业指导,可考虑利用统计学方法。通常不建议直接采用四分位数或中位数等划分方式,而应根据数据分布情况综合判断,必要时可咨询统计学家。
例2.某研究分析与肥胖有关的几个社会生活因素,作者最终给出了性别、年龄、职业、文化程度4个因素的分析结果,见表1。
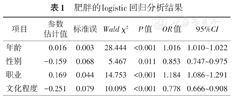
肥胖的logistic回归分析结果
肥胖的logistic回归分析结果
| 项目 | 参数估计值 | 标准误 | Wald χ2 | P值 | OR值 | 95%CI |
|---|---|---|---|---|---|---|
| 年龄 | 0.016 | 0.003 | 28.444 | <0.001 | 1.016 | 1.010~1.022 |
| 性别 | -0.159 | 0.068 | 5.467 | 0.011 | 0.853 | 0.747~0.975 |
| 职业 | 0.169 | 0.044 | 14.753 | <0.001 | 1.184 | 1.086~1.291 |
| 文化程度 | -0.251 | 0.079 | 10.095 | <0.001 | 0.778 | 0.666~0.908 |
案例分析:该结果的主要问题为将多分类自变量作为连续变量纳入模型分析。本研究中,职业、文化程度为多分类变量,实际中通常赋值为1、2、3、……等。如果将多分类自变量直接按连续变量纳入模型,其OR值反映了:从1到2、从2到3、从3到4,……,结局发生风险以相同的速度增加或降低。如表1中职业的OR值为1.184,反映了1、2、3、……之间肥胖的风险依次增加18.4%。这种解释通常不符合实际。假定有4种职业,分别为事业单位、企业、农业、服务业,将其分别赋值为1~4,并不代表这几种职业之间真实存在数值上的高低,赋值1~4只是出于分析方便。如果将其作为连续变量纳入模型,则默认了这几类之间存在等级顺序。
建议:多分类变量尽管习惯用1、2、3、……等数值表示,但除非确定它们存在明显的等级顺序,否则分析时需将其作为分类变量纳入模型。对于一个k类的自变量,如果将其作为分类变量纳入模型,会输出k-1个结果,分别反映了与参照类(由研究者根据专业情况指定)相比,其他类别发生结局的风险大小。表2显示了职业作为四分类时的结果,以农业作为参照类,服务业、企业、事业单位分别与农业相比的OR值等结果。
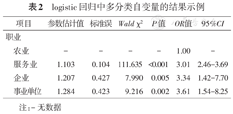
logistic回归中多分类自变量的结果示例
logistic回归中多分类自变量的结果示例
| 项目 | 参数估计值 | 标准误 | Wald χ2 | P值 | OR值 | 95%CI | |
|---|---|---|---|---|---|---|---|
| 职业 | |||||||
| 农业 | - | - | - | - | 1.00 | - | |
| 服务业 | 1.103 | 0.104 | 111.635 | <0.001 | 3.01 | 2.46-3.69 | |
| 企业 | 1.207 | 0.427 | 7.990 | 0.005 | 3.34 | 1.42-7.70 | |
| 事业单位 | 1.284 | 0.423 | 9.216 | 0.002 | 3.61 | 1.54-8.25 | |
注:-无数据
例3.某研究分析中老年2型糖尿病患者合并衰弱的影响因素,该研究共纳入153例研究对象,其中合并衰弱患者25例,无合并衰弱患者128例。作者探索了多个可能的因素,最终纳入了8个自变量进行分析。其中一个是微型营养评定(MNA)总分,作者根据总分将其分为3类,分别为0=营养状况良好(60例)、1=营养不良风险(36例)、2=明确营养不良(3例)。作者将"明确营养不良"作为参照类,最终结果分析显示,MNA对结局影响无统计学意义。
案例分析:该研究有两个潜在的风险:①样本量相对自变量数偏少;②在具体的MNA这一变量分析中,样本量明显不足。
关于样本量问题,由于logistic回归的参数估计常采用最大似然估计,该估计方法在样本量较小时很容易出现偏倚。统计模拟显示[6],每个自变量至少对应10例阳性结局,估计结果较为可靠,否则可能会出现偏倚。这里需要注意的是,应是阳性结局例数,而不是总例数。如本例中按前述原则,要估计8个自变量,应至少需要80例阳性结局例数,假定该研究中阳性结局的比例为25/153,则实际应需要至少80/(25/153)例,四舍五入后为490例。与至少应满足的490例相比,153例样本明显不足,结果可靠性值得推敲。
对于第2个问题,作者对MNA的分析中以例数最少的"明确营养不良"作为参照类,这种分析方式很容易导致本来有意义的变量变得无统计学意义。以本例数据为例,表3比较了以"营养状况良好"作为参照和以"明确营养不良"作为参照的结果。可以看出,"明确营养不良"为参照,由于例数太少(3例),导致其余两类与其相比均无统计学意义,从而得出该变量无统计意义的结论;而以"营养状况良好"为参照(60例),"营养不良风险"与其相比则有统计学意义。这种情况下,仍可认为该变量有统计学意义。
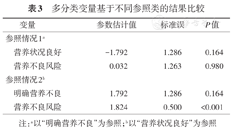
多分类变量基于不同参照类的结果比较
多分类变量基于不同参照类的结果比较
| 变量 | 参数估计值 | 标准误 | P值 | |
|---|---|---|---|---|
| 参照情况1a | ||||
| 营养状况良好 | -1.792 | 1.286 | 0.164 | |
| 营养不良风险 | 0.032 | 1.263 | 0.980 | |
| 参照情况2b | ||||
| 明确营养不良 | 1.792 | 1.286 | 0.164 | |
| 营养不良风险 | 1.824 | 0.500 | <0.001 | |
注:a以"明确营养不良"为参照;b以"营养状况良好"为参照
建议:logistic回归分析中,建议阳性结局的例数(而不是总例数)至少应为自变量个数的10倍以上。对于多分类自变量,选择参照类需要谨慎,尽量不要以例数最少的类别作为参照,否则会由于标准误太大而导致结果出现假阴性。
例4.某研究评价白细胞计数对心肌梗死患者ST段抬高的预测价值,作者采用病例对照研究,将结局分为ST段抬高和非ST段抬高,采用logistic回归分析白细胞计数对结局的预测价值。作者在文中提到,采用logistic回归对ST段抬高的危险因素进行筛选,最终结果显示,白细胞计数有统计学意义,因此认为白细胞计数对ST段抬高具有较好的预测价值。
案例分析:该研究的分析思路主要存在两个问题:①采用探索危险因素的分析思路来验证危险因素;②将自变量有统计学意义等同于自变量有较高预测价值。
logistic回归比较常见的两种应用目的为探索危险因素和验证危险因素。这两种思路在软件操作上并无太大不同,都是多因素分析,因此临床工作者很容易将二者混淆。探索危险因素常用于研究的初期阶段,此时研究者对结局发生的因素了解较少,通常根据专业知识或查阅文献等方式收集各种可能的因素并进行探索,以期发现哪些可能是结局发生的危险因素。而验证危险因素则通常是建立在研究者对结局已有一定认识的基础上,目的是为了验证某一因素是否为真正的影响因素,尽管也是多因素分析,但侧重分析主要研究因素,同时校正可能的混杂因素。例如,某地区研究胃癌的危险因素,初期一般为探索性分析,以了解胃癌的危险因素有哪些;如果在探索性分析中发现某一因素(如幽门螺杆菌)与胃癌的关联较大,则可进一步开展验证性分析,专门针对幽门螺杆菌开展相关研究,以验证幽门螺杆菌是否为胃癌的独立危险因素。
该研究中,目的是评价白细胞计数对心肌梗死患者ST段抬高的预测价值,有明确的研究因素,因此属于验证危险因素,而不是探索危险因素。其分析思路应为校正其他可能的混杂因素后,明确白细胞计数是否为心肌梗死患者ST段抬高的独立预测因子。而作者采用危险因素筛选的思路,将白细胞计数与其他变量同等看待进行筛选,这是一种错误的思路。
该研究的第2个问题与预测建模思路有关。事实上,该研究的分析结果并不能支持"白细胞计数具有较高预测价值"这一结论,只能说明白细胞对结局有一定的影响,但影响有多大,预测价值有多高,需要通过各种预测模型的评价指标来确定。
建议:对于验证危险因素的分析思路,不应采用变量筛选的方式(如逐步回归等),而应将研究变量(如该研究中的白细胞计数)始终纳入模型,同时校正其他可能的混杂因素,以发现研究因素与结局的真实关系。预测建模分析中,某指标的预测价值有多大,需要采用专门的指标进行评价,而不是根据P值是否有统计学意义来定。常见的预测模型评价指标有:受试者工作特征(receiver operating characteristic,ROC)曲线下面积、灵敏度、特异度、校准曲线等。另外,预测建模的思路也不同于危险因素筛选,预测建模通常需要将数据分为训练集和验证集,训练集用来建立模型,验证集用来验证模型的优劣,而不是简单地筛选变量。关于预测建模的详细思路可参考TRIPOD规范[7,8]。
综上,logistic回归分析并非简单地用统计软件得到一个输出结果,其分析过程中有不少需要注意的问题。以往文章已经介绍了logistic回归方法本身所需要注意的问题[1,2],本文则主要从分析思路角度介绍了医学中logistic回归应用的常见逻辑错误与注意事项。对于基层临床医生而言,了解这些基本逻辑和分析思路既是必要的,也是可掌握的。建议在应用logistic回归时,首先一定要明确研究目的,是为了探索危险因素还是校正混杂因素或建立预测模型,根据不同研究目的确定分析思路;其次要根据自变量的不同类型,确定纳入模型的不同形式,尤其是多分类自变量,不能简单将其作为连续变量纳入;此外还需要保证一定的样本量,不能只看总例数,更应关注每一类的例数。只有研究思路明确、样本例数合理、变量形式恰当,才有可能得到一个可靠的结果。
所有作者均声明不存在利益冲突

























