
近年来,有关预测模型的临床研究迅猛增加,用于预测模型的数据来源也日益丰富。越来越多的研究采用多中心、不同地区或国家、不同研究的多源数据集构建与验证预测模型。为了适应这些新的研究场景,基于多源数据的个体预后或诊断多因素预测模型报告规范(TRIPOD-Cluster)于2023年发布,其旨在加强全球研究者的规范报告,以促进更具普适性的临床预测模型构建与验证。本文从TRIPOD-Cluster制定过程、清单内容、适用场景、优势、常用建模方法等方面进行解读与讨论,以促进国内学者利用多源数据建立与验证多因素预测模型,提高这类研究报告的规范性。


版权归中华医学会所有。
未经授权,不得转载、摘编本刊文章,不得使用本刊的版式设计。
除非特别声明,本刊刊出的所有文章不代表中华医学会和本刊编委会的观点。
经全国继续医学教育委员会批准,本刊开设继教专栏,文后附5道单选题,读者阅读后可扫描标签二维码答题,每篇可免费获得Ⅱ类继教学分0.5分,全年最多可获5分
近年来,国内外有关预测模型的临床研究迅猛增加[1, 2, 3]。笔者于2018年解读了针对个体预后及诊断的多因素预测模型报告规范(Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis,TRIPOD),该报告规范是用以提高预测模型类研究质量及规范报告质量的国际标准工具[4, 5]。然而,用于预测模型的数据来源日益丰富,越来越多的研究采用多中心、不同地区或国家、不同研究的多源数据集(clustered data)[6]。为了适应这些新的研究场景,基于多源数据的个体预后或诊断多因素预测模型报告规范(Transparent Reporting of Multivariable Prediction Models Developed or Validated Using Clustered Data,TRIPOD-Cluster)应运而生,其旨在加强全球研究者的规范报告,以促进更具普适性的临床预测模型构建与验证[6]。本文对TRIPOD-Cluster报告规范进行解读,以促进国内学者的规范报告。
2023年TRIPOD-Cluster报告规范制定协作组在TRIPOD的基础上新研发了一个针对多源数据的预测模型报告清单[6]。TRIPOD-Cluster报告规范制定协作组制定清单过程严格遵循医学研究报告规范制定要求。该协作组审查了文献资料及网络数据库,在文献综述的基础上形成初稿;采用德尔菲专家咨询法向全球有预测模型研究经验的专家(包括统计学家、流行病学家、临床医师、期刊编辑)发放电子问卷收集修订建议,并召开多轮面对面专家会议,经过反复讨论修订,最终形成包含19个条目的TRIPOD-Cluster清单(表1),该报告规范在BMJ等国际知名期刊发表[6]。

基于多源数据的个体预后或诊断多因素预测模型报告规范(TRIPOD-Cluster)清单[6]
基于多源数据的个体预后或诊断多因素预测模型报告规范(TRIPOD-Cluster)清单[6]
| 条目 | 描述 |
|---|---|
| 标题与摘要 | |
| 1 | 明确研究为多因素预测模型的建立和(或)验证,明确目标人群及预测结局 |
| 2 | 提供研究目标、研究现场、研究对象、数据源、样本量、预测因子、结局指标、统计分析、结果和结论的摘要a |
| 前言 | |
| 3a | 解释研究背景(包括诊断或预后)、建立或验证预测模型的基本原理,包括对现有模型的文献引用以及本研究设计的优势a |
| 3b | 明确研究目标,包括描述本研究是预测模型的建立还是模型验证a |
| 方法 | |
| 4a | 描述研究对象和数据集的纳排标准a |
| 4b | 描述数据的来源,以及如何识别、申请和收集数据 |
| 5 | 解释样本量是如何得出的a |
| 6a | 定义模型预测的结局指标,包括评估方式和时间a |
| 6b | 定义用于建立或验证模型的所有预测变量,包括测量方式和时间a |
| 7a | 描述数据准备过程,包括数据清理、整合、连接和质量控制 |
| 7b | 描述对每个数据库的偏倚风险和适用性评估方法(例如:使用PROBAST) |
| 7c | 在验证时,建议比较验证数据集与建模数据集在定义和测量方面的任何差异a(例如:研究现场、纳入标准、结局、预测因子) |
| 7d | 描述缺失数据处理方法a |
| 8a | 描述在分析中如何处理预测变量 |
| 8b | 详述模型类型、模型构建所有过程(例如:任何预测变量选择和惩罚项)以及验证方法a |
| 8c | 描述如何处理模型参数值中多源数据集(例如:研究或现场)的任何异质性 |
| 8d | 在验证时,描述预测值的计算方式 |
| 8e | 指定用于评估模型性能的所有指标(例如:校准度、区分度和决策曲线分析),如果可能的话则比较多个模型 |
| 8f | 描述如何处理和量化多源数据集(例如:研究或现场)模型性能中的任何异质性 |
| 8g | 描述由验证导致的任何模型更新(例如:重新校准),无论是对整体的还是对特定人群或现场的a |
| 9 | 描述任何计划的亚组或敏感性分析(例如:根据不同偏倚来源、研究对象特征、研究现场来评估模型性能) |
| 结果 | |
| 10a | 描述从数据识别到数据分析的各类数据集及研究对象的数量,建议考虑使用流程图a |
| 10b | 报告每个数据源或研究现场的总体特征和适用性,包括关键日期、预测因子、所接受的治疗、样本量、结局事件数量、随访时间和缺失数据情况a |
| 10c | 在验证时,建议比较验证数据与建模数据在重要变量(人口学特征、预测因子和结局)上的分布差异 |
| 11 | 报告各个数据集中偏倚风险评估的结果 |
| 12a | 报告在模型建立过程中涉及到的任何多源数据集的异质性评估结果(例如:纳入或排除特定预测因子或数据集) |
| 12b | 呈现最终预测模型(例如:所有回归系数以及特定时间点的模型截距或基线估计值),并解释如何将其用于新个体的预测a |
| 13a | 报告整体和每个数据集的预测性能效应值及其置信区间 |
| 13b | 报告多源数据集的模型性能的任何异质性结果 |
| 14 | 报告任何模型的更新结果(包括更新的模型方程和后续性能),总数据集及每个数据集a |
| 15 | 报告任何亚组分析或敏感性分析的结果 |
| 讨论 | |
| 16a | 在研究目的和先前研究的背景下,对主要结果进行总体解释,包括模型性能在各数据集之间的异质性a |
| 16b | 在验证时,请参阅建模数据和任何先前验证中的模型性能来讨论结果 |
| 16c | 讨论研究的优势和任何局限性(例如:数据缺失或不完整、缺乏代表性、数据整合问题)a |
| 17 | 讨论该模型的潜在用途和对未来研究的影响,具体考虑该模型在不同场景或(亚)人群中的普遍性和适用性a |
| 其他信息 | |
| 18 | 提供有关补充材料及其来源信息(例如:研究方案、分析代码、数据集)a |
| 19 | 指明资金来源和资助者在本研究中的作用 |
注:PROBAST为预测模型偏倚风险评估工具;模型性能指模型的预测能力;a该条目是对原始TRIPOD清单中的1个或多个现有条目的改编
TRIPOD-Cluster报告规范中列出了包含19个条目的TRIPOD-Cluster清单(表1),该清单包括标题与摘要(条目1~2)、前言(条目3)、方法(条目4~9)、结果(条目10~15)、讨论(条目16~17)和其他信息(条目18~19),共计6个部分。TRIPOD-Cluster报告规范既可供多因素预测模型的建立类研究使用,也可供模型验证类研究使用。TRIPOD-Cluster英文版核对清单可以在线下载(www.tripod-statement.org)。
1. 适用场景:TRIPOD-Cluster是一个新的报告清单,它适用于基于多源数据的预测模型研究。研究者所整合的多源个体数据,可以是从电子医疗记录(electronic healthcare records,EHRs)中检索获得的个体参与者数据或者通过注册登记研究所获得;也可以是将多项研究的个体数据组合起来所开展的基于个体参与者数据的荟萃分析(individual participant data meta-analysis,IPD-MA)。简而言之,最常见的两种基于多源数据的场景是利用来自不同医疗机构或不同中心的EHRs或基于IPD-MA开展预测模型研究。对于重复测量数据,TRIPOD-Cluster则不适用。协作组给出了适用于TRIPOD-Cluster的研究示例(表2)[6, 7, 8, 9, 10, 11, 12, 13, 14]。
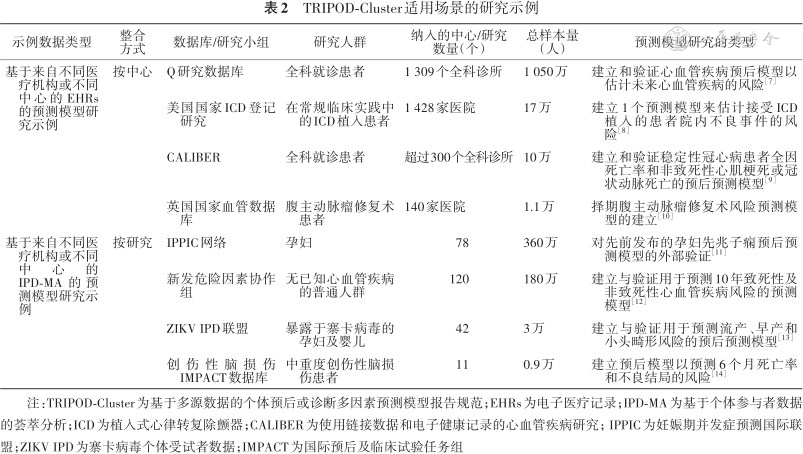
TRIPOD-Cluster适用场景的研究示例
TRIPOD-Cluster适用场景的研究示例
| 示例数据类型 | 整合方式 | 数据库/研究小组 | 研究人群 | 纳入的中心/研究数量(个) | 总样本量(人) | 预测模型研究的类型 |
|---|---|---|---|---|---|---|
| 基于来自不同医疗机构或不同中心的EHRs的预测模型研究示例 | 按中心 | Q研究数据库 | 全科就诊患者 | 1 309个全科诊所 | 1 050万 | 建立和验证心血管疾病预后模型以估计未来心血管疾病的风险[7] |
| 美国国家ICD登记研究 | 在常规临床实践中的ICD植入患者 | 1 428家医院 | 17万 | 建立1个预测模型来估计接受ICD植入的患者院内不良事件的风险[8] | ||
| CALIBER | 全科就诊患者 | 超过300个全科诊所 | 10万 | 建立和验证稳定性冠心病患者全因死亡率和非致死性心肌梗死或冠状动脉死亡的预后预测模型[9] | ||
| 英国国家血管数据库 | 腹主动脉瘤修复术患者 | 140家医院 | 1.1万 | 择期腹主动脉瘤修复术风险预测模型的建立[10] | ||
| 基于来自不同医疗机构或不同中心的IPD-MA的预测模型研究示例 | 按研究 | IPPIC网络 | 孕妇 | 78 | 360万 | 对先前发布的孕妇先兆子痫预后预测模型的外部验证[11] |
| 新发危险因素协作组 | 无已知心血管疾病的普通人群 | 120 | 180万 | 建立与验证用于预测10年致死性及非致死性心血管疾病风险的预测模型[12] | ||
| ZIKV IPD联盟 | 暴露于寨卡病毒的孕妇及婴儿 | 42 | 3万 | 建立与验证用于预测流产、早产和小头畸形风险的预后预测模型[13] | ||
| 创伤性脑损伤IMPACT数据库 | 中重度创伤性脑损伤患者 | 11 | 0.9万 | 建立预后模型以预测6个月死亡率和不良结局的风险[14] |
注:TRIPOD-Cluster为基于多源数据的个体预后或诊断多因素预测模型报告规范;EHRs为电子医疗记录;IPD-MA为基于个体参与者数据的荟萃分析;ICD为植入式心律转复除颤器;CALIBER为使用链接数据和电子健康记录的心血管疾病研究;IPPIC为妊娠期并发症预测国际联盟;ZIKV IPD为寨卡病毒个体受试者数据;IMPACT为国际预后及临床试验任务组
2. 基于多源数据建模与验证的优势:单一数据建模具有一定局限性。首先,基于单一中心/研究(例如单个医院或诊所)所建立的预测模型通常是源于单个且较小的数据集,很容易造成预测模型的过度拟合问题。其次,在预测模型建立过程中,如果不考虑不同中心/研究的数据集之间的差异性(即异质性),那么当所构建的模型被应用于其他中心、地区或研究的数据时模型的预测能力(即模型性能)可能会不佳。因此,对于采用单一中心/研究数据所构建的传统预测模型,通常其通用性十分有限。同样,当在预测模型验证过程中,忽略不同中心/研究数据之间的异质性时,对预测模型性能的估计也会具有很大的误导性。单一数据建模无法显示出在多个医疗实践、中心或国家/地区的普适性[15],因此许多已构建的预测模型在应用于新患者时表现不佳[16]。为了克服这些问题,越来越多的研究者在使用大型多源数据集进行预测模型研究。基于多源数据构建预测模型可以较好地弥补上述单一数据建模的不足。当使用整合的多源数据集时,由于同一数据集的不同个体通常经历了相似的诊疗流程(例如同样的诊疗流程由同类医疗服务者提供),因此可能比来自不同数据集的个体更为相似(同质性);不同数据集的研究对象可能在患者基线个体特征、结局发生风险、预测模型效应值等方面存在差异(异质性)。因此,整合多源数据的最重要优势是使研究者能够利用多来源、多中心、多区域或国家的数据直接测试预测模型的性能(例如模型的校准度和区分度)和普适性,探索不同子集间差异(异质性)。通过识别异质性的来源有助于更好地调整或匹配这些来自不同子集的模型,从而构建出更具普适性的临床预测模型,支持临床决策。总之,使用多源数据集进行预测建模的显著优势是提高了模型的预测性能,并有助于开发、验证和更新更适用于多种类型数据集群的预测模型。
3. 常用建模方法:传统基于单一数据的预测模型结合许多变量特征(预测变量或协变量等)来产出个体诊断和(或)预后的相关预测概率或风险。它们可采用常用的多因素回归方法进行构建,例如logistic回归、Cox比例风险回归、线性回归或多项式回归等。此外,近年来也有越来越多的研究使用神经网络、支持向量机和随机森林等机器学习算法来建立预测模型。一般而言,对于基于多源数据建模的研究,建议采用专门针对多源数据的方差估计方法(例如随机效应模型),以允许基线特征和预测效应中多源数据集的异质性,从而产生具有不同数据集群的不同截距和预测效应的预测模型。随机效应模型在模型验证期间可能还需要评估多源数据集预测模型性能的异质性,以便更深入地了解模型不满足的条件及其数据集群特征。在敏感性分析中,可以考虑调整集群级别变量的分组方式,或者改变变量选择算法等方式,来评估和减少预测模型中不同多源数据集间的异质性大小。总之,应充分报告预测模型研究中用于探索和解释不同数据集间统计异质性的策略。与传统基于单一数据的预测模型相比,研究者还可以利用多源数据集更好地探索更复杂和预测性能更好的模型,例如对预测因子效应的非线性估计、预测因子间的相互作用、时间依存系数和时间依存协变量等。单一数据建模与多源数据建模的特征及其优缺点比较见表3。

基于单一数据与多源数据建模与验证的特征及其优缺点比较
基于单一数据与多源数据建模与验证的特征及其优缺点比较
| 比较维度 | 单一数据建模与验证 | 多源数据建模与验证 | |
|---|---|---|---|
| 数据 | 单个中心/研究/地区数据 | 多个中心/研究/地区的多源数据 | |
| 适用报告规范 | TRIPOD | TRIPOD-Cluster | |
| 样本量 | 较小 | 较大 | |
| 模型普适性 | 有限,且无法直接检验模型的普适性 | 较强,且可以直接检验模型的普适性 | |
| 过度拟合问题 | 容易产生 | 不易产生 | |
| 数据可获得性 | 单一数据集较易获得 | 多源数据集相对较难获得 | |
| 统计方法 | 相对简单,常用模型包括logistic回归、Cox比例风险回归、线性回归、多项式回归等 | 相对复杂,可使用随机效应模型、机器学习等 | |
| 预测因子与结局的关联 | 难以研究更复杂但更具预测性的关联 | 可以研究更复杂但更具预测性的关联,可分析预测因子的非线性效应、预测因子相互作用以及依时变量效应等复杂统计内容 | |
注:TRIPOD为针对个体预后及诊断的多因素预测模型报告规范;TRIPOD-Cluster为基于多源数据的个体预后或诊断多因素预测模型报告规范
4. 与原TRIPOD清单比较:与原TRIPOD清单相比,TRIPOD-Cluster删除与合并了TRIPOD的22个条目,并纳入了10个新的条目,包括研究多源数据的识别、数据准备、偏倚风险评估、预测模型参数异质性、预测模型性能估计异质性以及亚组及敏感性分析等内容。例如:条目4b(描述数据的来源,以及如何识别、申请和收集数据)、条目7a(描述数据准备过程,包括数据清理、整合、连接和质量控制)、条目7b(描述对每个数据库的偏倚风险和适用性评估方法,例如使用PROBAST)、8c(描述如何处理模型参数值中多源数据集的任何异质性)、8f(描述如何处理和量化多源数据集模型性能中的任何异质性)、9(描述任何计划的亚组或敏感性分析,例如根据不同偏倚来源、研究对象特征、研究现场来评估模型性能)、11(报告各个数据集中偏倚风险评估的结果)、12a(报告在模型建立过程中涉及到的任何多源数据集的异质性评估结果,例如纳入或排除特定预测因子或数据集)等。当基于多源数据进行预测模型研究时,研究人员需要采用比既往仅采用单一数据源的常规预测模型研究更具体的方法进行设计、分析和报告,以便读者可以科学评价研究方法和结果。
近年来,医疗健康大数据给临床研究带来了新的机遇,越来越多的学者采用多源数据来构建与验证个体诊断或预后的预测模型,但所使用数据的多源性、异质性和统计分析的复杂性也给预测模型的建立和验证带来了新的挑战。TRIPOD Cluster报告规范旨在有效地规范和引导基于多源数据的预测模型类研究论文的报告,让预测模型的建立者、使用者和评价者都能够很好地对该类预测模型有全面的认识和了解,同时可以指导学者们对该类预测模型的进一步研究与修正。为了便于学术编辑、同行评议专家和读者对文章进行阅读,在基于多源数据的预测模型类文章投稿时建议将TRIPOD Cluster核查清单作为附件提交。
高质量多源数据的可获得性对学界开展基于多源数据的预测模型研究至关重要。尽管目前我国医学领域临床实践过程中已经自然产生了大量健康医疗数据,但不同部门、不同中心、不同研究间数据割裂现象依然存在,且不同来源数据的质量参差不齐,这均不利于数据的有效整合利用。未来应进一步规范临床真实世界数据的采集过程与质量,整合多源数据资源,打破不同医疗机构与信息系统的数据壁垒,加强开展多中心的集成研究,从而加快积累与形成我国高质量多源医疗健康大数据,为开展基于多源数据的临床预测模型研究提供坚实的数据与平台基础,进而形成普适性的预测模型,惠及更多患者,助力临床实践决策。
陶立元, 刘珏. 基于多源数据的个体预后或诊断多因素预测模型报告规范(TRIPOD-Cluster)解读[J]. 中华医学杂志, 2023, 103(36): 2893-2897. DOI: 10.3760/cma.j.cn112137-20230606-00952.
所有作者声明不存在利益冲突
1.适用于基于多源数据的个体预后或诊断多因素预测模型的报告规范是()
A.TRIPOD
B.TRIPOD Cluster
C.STROBE
D.AGREE
2.基于多源数据的个体预后或诊断多因素预测模型的报告规范清单一共有几个条目?()
A.19
B.20
C.21
D.22
3.以下说法错误的是()
A.单一数据建模与验证通常采用单个中心/研究/地区数据
B.多源数据建模与验证通常采用多个中心/研究/地区的多源数据
C.单一数据建模与验证采用TRIPOD报告规范
D.多源数据建模与验证采用TRIPOD报告规范
4.以下说法正确的是()
A.单一数据建模与验证通常样本量较大
B.多源数据建模与验证通常样本量较大
C.单一数据建模与验证不容易产生过拟合问题
D.多源数据建模与验证容易产生过拟合问题
5.以下说法正确的是()
A.单一数据建模与验证可以用于研究更复杂但更具预测性的关联
B.多源数据建模与验证不能用于研究更复杂但更具预测性的关联
C.单一数据建模与验证的数据可获得性差
D.TRIPOD Cluster是于2023年被研发出来的

























