
本讲概述基于病因探索的队列研究的学术定义、基本原理、设计要点、研究对象与样本量估算、分析指标、统计分析方法、报告撰写规范和经典研究案例。
版权归中华医学会所有。
未经授权,不得转载、摘编本刊文章,不得使用本刊的版式设计。
除非特别声明,本刊刊出的所有文章不代表中华医学会和本刊编委会的观点。
本讲概述基于病因探索的队列研究的学术定义、基本原理、设计要点、研究对象与样本量估算、分析指标、统计分析方法、报告撰写规范和经典研究案例。
队列研究(cohort study)也称前瞻性研究(prospective study)、随访研究(follow-up study)、纵向研究(longitudinal study)等。队列研究是将队列人群按照是否暴露于某个研究因素以及暴露等级不同分为不同的研究组,追踪随访适当长的时间,比较不同研究组之间疾病或结局发生率的差异,来判定暴露因素与结局(与暴露因素有关的结局)之间有无关联及关联大小的一种观察性研究方法[1]。队列研究的最主要目的是探索病因,即进一步验证现况调查或病例对照研究中已发现的有特异影响、且在统计学上有联系的危险(或保护)因素。
如图1所示,队列研究的基本原理是选定一组研究人群,根据过去或目前的暴露情况进行分组[按有无暴露因素分组:暴露组和对照组(非暴露组);按暴露因素的水平分组:低、中、高剂量组],随访观察各组的结局(发病或死亡),比较各组发病率或死亡率(Ie与I0)的差异,从而判定暴露因素与发病有无因果关联及关联大小。
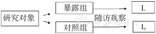
根据暴露的自然存在状态分组,无人为控制,也不存在随机分组;
从"因"到"果",确证暴露因素与疾病的因果关系。
能准确计算出结局的发生率(如发病率、死亡率等率的指标),估计暴露人群发生某结局的危险程度。
队列研究的研究对象是还没出现研究结局,但有可能出现研究结局的人群(susceptible population),需设立纳入及排除标准,剔除已生病个体或明确不会生病的个体,在进行传染病危险因素的研究时,需考虑个体被感染的概率。
队列研究的样本量估算需要事先确定以下参数:一般人群(非暴露组的)所研究疾病的发病率或死亡率p0、暴露组所研究疾病的发病率或死亡率p1以及显著性水准(第一类错误概率)α(一般取值0.05)和把握度(1-β),β为第二类错误概率,一般取值0.2。然后代入公式进行推算:
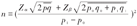
式中p0、p1分别表示对照组与暴露组的发病概率。q0=1-p0、q1=1-p1、 、
、 。Zα与Zβ分别为对应于α和β的标准正态界值。Z0.05=1.64,Z0.20=0.84。
。Zα与Zβ分别为对应于α和β的标准正态界值。Z0.05=1.64,Z0.20=0.84。
队列研究数据可以采用四格表进行整理(见表1),并根据研究目的计算有关分析指标(见表2)。

队列研究设计图
队列研究设计图
| 组别 | 发病数 | 未发病数 | 发病率 |
|---|---|---|---|
| 暴露组 | a | b | Ie=a/(a+b) |
| 对照组(非暴露) | c | d | I0=c/(c+d) |
| 合计 | a+c=D | b+d | It=D/(a+b+c+d) |
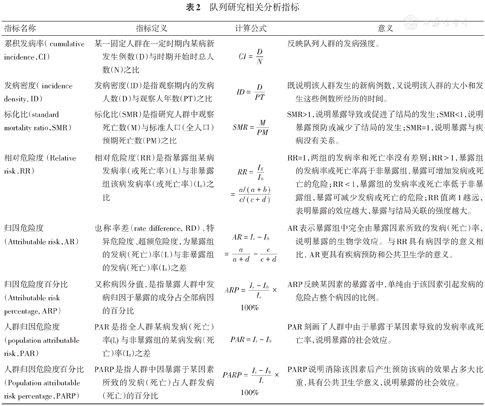
队列研究相关分析指标
队列研究相关分析指标
| 指标名称 | 指标定义 | 计算公式 | 意义 |
|---|---|---|---|
| 累积发病率( cumulative incidence,CI) | 某一固定人群在一定时期内某病新发生例数(D)与时期开始时总人数(N)之比 | 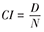 | 反映队列人群的发病强度。 |
| 发病密度( incidence density, ID) | 发病密度(ID)是指观察期内的发病人数(D)与观察人年数(PT)之比 | 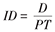 | 既说明该人群发生的新病例数,又说明该人群的大小和发生这些例数所经历的时间。 |
| 标化比(standard mortality ratio,SMR) | 标化比(SMR)是指研究人群中观察死亡数(M)与标准人口(全人口)预期死亡数(PM)之比 | 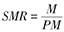 | SMR>1,说明暴露导致或促进了结局的发生;SMR<1,说明暴露预防或减少了结局的发生;SMR=1,说明暴露与疾病没有关系。 |
| 相对危险度(Relative risk,RR) | 相对危险度(RR)是指暴露组某病发病率(或死亡率)(Ie)与非暴露组该病发病率(或死亡率)(I0)之比 | 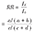 | RR=1,两组的发病率和死亡率没有差别;RR>1,暴露组的发病率或死亡率高于非暴露组,暴露可增加发病或死亡的危险;RR<1,暴露组的发病率或死亡率低于非暴露组,暴露可减少发病或死亡的危险;RR值离1越远,表明暴露的效应越大,暴露与结局关联的强度越大。 |
| 归因危险度(Attributable risk,AR) | 也称率差(rate difference, RD)、特异危险度、超额危险度,为暴露组的发病(死亡)率(Ie)与非暴露组的发病(死亡)率(I0)之差 | 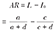 | AR表示暴露组中完全由暴露因素所致的发病(死亡)率,说明暴露的生物学效应。与RR具有病因学的意义相比,AR更具有疾病预防和公共卫生学的意义。 |
| 归因危险度百分比(Attributable risk percentage, ARP) | 又称病因分值,是指暴露人群中发病归因于暴露的成分占全部病因的百分比 | 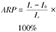 | ARP反映某因素的暴露者中,单纯由于该因素引起发病的危险占整个病因的比例。 |
| 人群归因危险度(population attributable risk,PAR) | PAR是指全人群某病发病(死亡)率(It)与非暴露组的某病发病(死亡)率(I0)之差 | 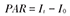 | PAR刻画了人群中由于暴露于某因素导致的发病率或死亡率,说明暴露的社会效应。 |
| 人群归因危险度百分比(Population attributable risk percentage,PARP) | PARP是指人群中因暴露于某因素所致的发病(死亡)占人群发病(死亡)的百分比 | 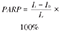 | PARP说明消除该因素后产生预防该病的效果占多大比重,具有公共卫生学意义,说明暴露的社会效应。 |
队列研究是在病例随访表的基础上,建立队列研究的基线数据库及随访数据库,然后进行资料的清洗、核查,填补缺失数据,锁定数据库。对队列研究资料可采用统计描述、统计推断、统计模型和统计模拟进行统计分析。
即采用队列研究的特征性指标去描述两组研究对象的基线特征、随访时间、失访比例、两组的可比性;采用队列研究的分析指标去描述暴露组和非暴露组研究结局(疾病的发生、治愈或死亡)的发生率(治愈率、死亡率)、累积发病率、发病密度、标化比、相对危险度、归因危险度、归因危险度百分比、人群归因危险度等指标。
即采用U检验、χ2检验、生存分析等方法去推断暴露组和非暴露组研究结局的发生率之间的差异。若两组研究结局发生率经统计学检验有差异,则可进一步分析暴露与结局的关联性强度。在实际工作中,常将致病因素分为由低至高的几个不同的暴露水平,采用检验方法进行反应与剂量间是否存在线性趋势的假设检验,以便更好地揭示出某致病因素的暴露水平与发病率之间的剂量-反应关系(dose-response relationship)。
即采用Cox回归和logistic回归等统计模型去分析判断多个暴露因素与研究结局之间的关联程度(因果联系)以及多个暴露因素之间的交互作用。
即采用蒙特卡罗模型与分层抽样模拟算法去估算一个队列中暴露因素对研究结局的关联程度和潜伏期。
在撰写队列研究的结果报告和论文时,可参照加强观察性流行病学研究报告的质量规范(strengthening the reporting of observational studies in epidemiology,STROBE)中的要求进行[2]。该规范可从网上免费下载,网址为:http://www.strobe-statement.org/fileadmin/Strobe/uploads/checklists/STROBE_checklist_v4_cohort.pdf. STROBE报告指南22个条目介绍见表3。

STROBE报告指南22个条目介绍
STROBE报告指南22个条目介绍
| 条目名称 | 条目编号 | 推荐内容 | |
|---|---|---|---|
| 题目和摘要 | 1 | a.在题目或摘要中使用常用术语表明研究采用的设计 | |
| b.在摘要中对所做工作和获得的结果做一个简明的总结 | |||
| 引言 | |||
| 背景/原理 | 2 | 解释研究的科学背景和原理 | |
| 目的 | 3 | 阐明具体研究目的,包括任何预先设定的假设 | |
| 方法 | |||
| 研究设计 | 4 | 陈述研究设计的关键内容 | |
| 研究设置 | 5 | 描述研究机构、研究地点及相关资料,包括招募的时间范围、暴露、随访和数据收集等 | |
| 参与者 | 6 | a.队列研究—描述纳入标准,参与者的来源和选择方法,随访方法;随机对照试验--描述纳入标准,病例和对照的来源,及确定病例和选择对照的方法;横断面调查--描述纳入标准及参与者的来源和选择方法 | |
| b.队列研究—对于配对设计,应说明配对标准及暴露和未暴露的人数;病例对照研究—对于配对设计,应说明配对标准和每个病例配对的对照数 | |||
| 变量 | 7 | 明确定义结局、暴露、预测因子、可能的混杂因素及效应修饰因素。如果相关,给出诊断标准 | |
| 数据来源/测量 | 8* | 对每个有意义的变量,给出数据来源和详细的测量方法。如果有一个以上的组,请描述各组之间测量方法的可比性 | |
| 偏倚 | 9 | 描述解决潜在偏倚的方法 | |
| 样本量大小 | 10 | 描述样本量的确定方法 | |
| 定量变量 | 11 | 解释定量变量是如何分析的。如果相关,描述分组的方法和原因 | |
| 统计方法 | 12 | a.描述所有统计方法,包括用于控制混杂因素的方法 | |
| b.描述所有亚组分析和交互作用的方法 | |||
| c.解释如何处理缺失数据 | |||
| d.队列研究--(如果相关)描述处理失访问题的方法;病例对照研究--(如果相关)描述如何对病例和对照进行配对;横断面研究--(如果相关)描述考虑到抽样策略的分析方法 | |||
| e.描述所用的敏感性分析方法 | |||
| 结果 | |||
| 参与者 | 13 | a.报告研究各阶段参与者的人数,如可能合格的人数,参与合格性检查的人数、确认合格的人数、纳入研究的人数、完成随访的人数和完成分析的人数 | |
| b.解释在各阶段参与者退出研究的原因 | |||
| c.考虑使用流程图 | |||
| 描述性数据 | 14 | a.描述参与者的特征(例如人口统计学、临床和社会特征)以及暴露和潜在混杂因素的相关信息 | |
| b.描述就每一个待测变量而言缺失数据的参与者人数 | |||
| c.队列研究—总结随访时间(如平均随访时间和总随访时间) | |||
| 结局数据 | 15 | 队列研究—报告随时间变化的结局事件数或综合指标 | |
| 病例对照研究—报告各种暴露类别人数或暴露综合指标 | |||
| 横断面研究—报告结局事件数或综合指标 | |||
| 主要结果 | 16 | a.给出未校正的估计值,如果相关,给出混杂因素校正后的估计值及其精确度[如95%置信区间(confidence interval,CI)],阐明校正了哪些混杂因素及选择这些因素进行校正的原因 | |
| b.如对连续变量进行分组,要报告每组观察值的范围 | |||
| c.如果相关,对有意义的危险因素,最好把相对危险度转化成针对有意义的时间范围的绝对危险度 | |||
| 其他分析 | 17 | 报告完成的其他分析,如亚组分析、交互作用分析和敏感性分析 | |
| 讨论 | |||
| 关键结果 | 18 | 根据研究目标概括关键结果 | |
| 局限性 | 19 | 讨论研究的局限性,包括潜在偏倚或不准确的来源。讨论任何偏倚的方向和大小 | |
| 解释 | 20 | 结合研究目标、研究局限性、多重分析、相似研究的结果和其他相关证据,对结果进行谨慎全面的解读 | |
| 可推广性 | 21 | 讨论研究结果的可推广性(外推有效性) | |
| 其他信息 | |||
| 资金来源 | 22 | 提供研究资金来源和资助机构在研究中的作用,如果相关,提供资助机构在本项目原始研究中的作用 | |
注:在病例对照研究中应提供病例组和对照组的信息,在队列研究和横断面研究中应提供暴露组和未暴露组的信息。
国外最著名的队列研究案例是1964年英国学者Doll R和Hill A.B将4万名英国注册医生分为吸烟、不吸烟组,观察两组肺癌发病率,年平均发病率分别为1.66%和0.07%,强烈提示吸烟的致癌作用。Doll和Hill应用队列研究方法阐明了吸烟和肺癌的关系,为研究多种癌症的病因和原因未明的疾病提供了一个典范[3]。Doll和Hill在"肺癌及其他死因与吸烟之关系"中宣布吸烟与肺癌有因果联系,并由此提出了作为因果关系推断标准的Hill准则,包括9项标准:(1)时间顺序(temporal order);(2)关联强度(strength of association);(3)剂量反应关系(dose-response relation);(4)结果的一致性(consistency);(5)实验证据(experimental evidence);(6)合理性(plausibility);(7)生物学一致性(coherence);(8)特异性(specificity);(9)相似性(analogy)。在Hill准则的基础上,1991年美国流行病学家Marvyn Susser增加了预测力(predictive performance)一项[4],使该准则共有10项标准。该准则用于建立推定原因和观察效应之间因果关系的流行病学证据,被广泛应用于公共卫生研究[5]。
国内队列研究的著名案例较多,如华中科技大学公卫学院邬堂春院士牵头开展的"东风同济队列研究"就取得了多项成果。其中,为探讨饮酒与中老年男性2型糖尿病(T2DM)发病风险的关联性[6],邬堂春队列研究团队利用东风同济队列,于2008年在湖北省招募了27009名东风汽车公司离、退休职工,基线调查采用半结构化问卷收集饮酒信息和相关协变量,并进行了体格检查、血糖和血脂等测定。从队列中选取男性并排除基线调查时已患糖尿病、冠心病、卒中和恶性肿瘤者,最终纳入6784名男性。2013年进行随访,通过研究对象的医疗保险号收集其疾病或死亡结局,应用COX比例风险模型分析不同饮酒特征和模式与T2DM的关联性。研究结果表明:总体上饮酒与T2DM发生风险无关,但平均乙醇摄入量>20g/d或饮酒频率>7次/周会增加T2DM发生风险。
所有作者均声明不存在利益冲突

























