
听诊器是临床医师最常用的诊断工具,现代医学始于听诊器的发明。听诊器应用于临床已有200年历史,从最早的声学听诊器到现在的电子听诊器,其外形和传音方式经历了较大的变化,但其使用方式和临床使用价值并没有发生质的改变。随着信息技术的发展,人工智能应用于肺音的智能识别技术得到了更多的关注。本文介绍了听诊器的发展史、呼吸音的分类、传统听诊器与电子听诊器的优缺点比较和肺音智能识别技术发展的必要性如医疗资源不足、医师听诊存在主观性及电子听诊器的优势和需要改进的方向等问题;总结了电子听诊器辅助疾病诊断近年的研究进展;从肺音的标准化收集与建库、数字呼吸音的标注和定性、数据的处理、计算机肺音分析、电子肺音的可听和可视化展现等角度论述了肺音智能识别技术的现实可行性;分析了肺音领域研究目前存在的问题及改进建议;并展望了今后肺音智能识别技术的可能应用场景和使用价值。


版权归中华医学会所有。
未经授权,不得转载、摘编本刊文章,不得使用本刊的版式设计。
除非特别声明,本刊刊出的所有文章不代表中华医学会和本刊编委会的观点。
听诊器自发明以来已有200多年,外形和传音方式经历了一些演变,但其主要还是作为医师使用的工具而存在。由于非医学专业人士缺乏医学相关知识,因此听诊器的使用群体是有限的。截至2021年,我国拥有约14亿人口,卫生技术人员却仅有1千万左右[1],占总人口约7‰,因此医疗资源相对不足。近些年来由于空气污染、急性呼吸道传染病(流行性感冒等)等问题的影响,呼吸系统疾病患病人数不断增加,给医疗资源造成了更大负担。因此患者在家对自身健康的管理显得尤为重要,家庭医学-智能判读的听诊器对疾病预警和辅助早期诊断是人们广泛需要的。
早在希波克拉底时期,胸部听诊就已经作为一种疾病诊断的手段为医师所使用。当时由于听诊器尚未诞生,因此医师只能以耳朵贴住患者身体来听取肺音[2],若遇到男医师给女患者看病的情况,此时给医患双方均带来了不便。直到1816年法国医师Laennec发明了听诊器[2],这种尴尬的查体方式才被取代。早期的听诊器为声学听诊器,由听诊头、导音管和耳挂组成。1999年,美国3M™ Littmann公司研制并生产出电子听诊器。与传统听诊器相比,电子听诊器不仅能够根据听诊需要将声音清晰地扩大数10倍,具有较好的环境降噪效果,音质佳和保真度高,而且能够录制和存储听诊的声音[3,4]。因此基于电子听诊器的录音和存储功能以及现代信息技术的发展,近年来具有呼吸音判读功能的智能听诊器的研发成为了肺音领域研究的热点。
根据第7次人口普查结果显示,全国总人口为1 443 497 378人,而《2020年中国卫生健康统计年鉴》显示,截至2019年底,卫生技术人员(包括职业医师、职业助理医师、护士、药师、技师等)仅有10 154 010人[1],占总人口的7‰,平均142个人才能分配到1位医疗技术人员,人均医疗资源稍显不足。此外,随着工业化进程的发展,我国空气质量下降,呼吸系统疾病患病人数逐年上升,给医疗系统带来了较大负担。因此当患者起病至预约门诊或住院期间,常常缺乏对自身呼吸状况监测的有效手段。
听诊器具有无创、使用方便、价格实惠、无放射性等优点,且听诊器检查可快速重复,被广泛使用,但声学听诊器没有录音和存储功能,因此传统听诊的结果是主观的,它取决于医师的临床经验和听觉感知能力。人在呼吸时,气流通过呼吸道和肺泡,产生湍流引起振动,发出声响,通过肺组织及胸壁传至体表的声音,即为呼吸音。呼吸音大致可分为正常呼吸音和异常呼吸音,由于呼吸音分类多,临床经验不等的医师对于不同呼吸音的辨别能力不可避免地存在差异。多项研究表明,使用标准的双耳听诊器来检测异常呼吸音,听者之间存在显著的差异[5,6,7]。另一项研究发现,肺科医师对呼吸音判断的表现优于其他专科医师,实习医师和儿科医师的表现仅次于医学生和其他专科医师[8]。一般来说医师的资历深浅、科别等都对呼吸音的判断存在差异。未能正确识别呼吸音将对临床工作产生不利影响,可能导致疾病的错误诊断,延误患者的治疗,以及过度依赖胸片、CT等影像学检查,导致医疗资源浪费或其他一些问题[9]。所以,亟需一种将呼吸音听诊变成客观检查的方法——人工智能(artificial intelligence,AI)辅助诊断来提高呼吸系统疾病诊断的效率和准确率。呼吸音的分类见表1。

呼吸音分类
呼吸音分类
| 正常呼吸音 | 异常呼吸音 | ||||
|---|---|---|---|---|---|
| 异常肺泡呼吸音 | 异常支气管呼吸音 | 异常支气管肺泡呼吸音 | 啰音 | 胸膜摩擦音 | |
| 支气管呼吸音;支气管肺泡呼吸音;肺泡呼吸音;气管呼吸音 | 肺泡呼吸音减弱或消失;肺泡呼吸音增强;呼气音延长;断续性呼吸音;粗糙性呼吸音 | 也称管样呼吸音,正常肺泡呼吸音部位听到支气管呼吸音 | 正常肺泡呼吸音部位听到支气管肺泡呼吸音 | 干啰音(如哮鸣音、鼾音等);湿啰音(可分大、中、小) | 脏层胸膜和壁层胸膜变粗糙,摩擦产生 |
电子听诊器在一定程度上弥补了传统听诊器在声音数据存储和共享方面的劣势。它将声音信号转化为电子信号,电子信号通过音频处理软件进一步转化成波形图及频谱图,实现可视化,使得频谱分析成为可能。这是传统听诊器无可比拟的重要进步和优点,且可通过滤波等手段降低或过滤环境噪音,提高听诊的清晰度。然而,目前未见电子听诊器能提高呼吸音识别的准确度和效率的报道[10]。此外,现今市面上的听诊器使用人群以医务人员为主,患者无法像使用血压计、血糖仪、血氧仪等商业化医疗器械一样通过听诊器来进行自我监测。在大规模呼吸道传染病如新型冠状病毒肺炎流行期间,医师不便使用听诊器来对新型冠状病毒肺炎患者进行近距离听诊,使得患者缺乏呼吸音监测[4]。AI辅助诊断可以在保留普通听诊器优点的基础上,完善这些不足,是听诊技术发展的一大进步。传统声学听诊器与电子听诊器的优缺点比较见表2。

传统声学听诊器与电子听诊器的优缺点比较
传统声学听诊器与电子听诊器的优缺点比较
| 比较项目 | 传统声学听诊器 | 电子听诊器 |
|---|---|---|
| 价格 | 低 | 高 |
| 音量 | 低 | 可扩大数10倍 |
| 环境降噪效果 | 差 | 好 |
| 录音与存储功能 | 无 | 有 |
| 可视化 | 不能实现肺音的可视化 | 可在一定条件下将肺音转换为波形图和频谱图 |
此前,有一些研究聚焦于电子听诊器对呼吸系统疾病的诊断。Shimoda等[11]研究发现100~195 Hz低频下呼气:吸气肺音功率比(the expiration-to-inspiration sound power ratio in a low-frequency range,E/I LF)与脉冲振荡指标X5关系显著,可作为评价支气管哮喘(哮喘)患者相对外周气道阻塞的指标。他们另一项关于肺音分析的研究发现哮喘患者的E/I LF显著高于健康组,痰嗜酸粒细胞百分比>3%组的E/I LF显著高于<3%组,可作为评估哮喘患者控制水平的指标[12]。
还有一些研究结合AI,探索自动分析算法来辅助疾病的诊断。Srivastava等[13]提出了基于卷积神经网络的深度学习辅助模型来为COPD检测提供详细和严格的医疗呼吸音频数据分析,该系统还可以判断疾病的严重程度。Porter等[14]使用852个咳嗽声数据集结合临床诊断完善了自动咳嗽分析算法,在检测常见的儿童呼吸系统疾病,包括肺炎、哮喘、喉炎、毛细支气管炎以及上、下呼吸道疾病方面具有良好的诊断准确度,该诊断算法通过从咳嗽音频样本中提取数字特征而开发,使用选定的特征构建分类器模型[15]。
呼吸音数据采集的工具是具有录音功能的电子听诊器(如Littmann 3200电子听诊器),数据采集的对象为正常人和各种呼吸系统疾病患者(如COPD、哮喘、间质性肺疾病等),采集的部位为几个主要的呼吸音听诊部位(包括喉部、前胸和后背等),一般每个部位至少应采集2个以上的呼吸周期,随着样本量的增加,呼吸音数据库得以充实[16]。目前该领域研究多为对单一疾病的呼吸音研究,各研究团队所建肺音库数据比较单一,收集的呼吸音数量多为几十至上百条。随着近年来深度学习算法的兴起,对数据量的要求提升至上千条,使得建库的难度进一步增加。
数据收集完成后,需要临床医师对每一条音频进行标注,将其定性为正常、湿啰音或哮鸣音。由于在这个环节可出现因标注者的主观判断而影响准确度,因此建立一个金标准是极其重要的。在心脏听诊领域,一项研究将3位心脏病专家的研究结果作为金标准来量化电子听诊器和手持式超声仪在评估心脏杂音方面的效用[17],因此参考该研究,将3位呼吸内科医师的一致观点作为金标准,当其中2位意见存在分歧,则组织重新听取鉴别,消除歧义后录用数据,这样使标注结果尽可能客观。
为了保证获取的音频质量,还需对音频进行心肺音预处理和心肺音分离。首先要将模拟信号转换成数字信号,经过处理后再转换成模拟信号。数字信号特点是低频、非线性,是心音和肺音的混叠信号,受到采集设备及外部环境的影响,通常信号比较弱,噪声较强,随机性较强。预处理过程主要是小波去噪、预加重、分帧和加窗。小波去噪的基本思想是将原始心肺音信号通过小波分解后,通过选取一个合适的阀值,大于阀值的小波系数被认为是真实心肺音产生的,予以保留;小于阀值的则认为是噪声产生的,置为零,从而达到去噪的目的。预加重目的是提高音频中的高频分量,增加语音的高频分辨率,将尖锐的噪声影响降低。心肺音信号整体上不稳定,但局部上(10~30 ms)可以看作是稳定的,因此需要对整个心肺音信号进行分帧处理,即将其分割成多个片段再进行计算。心音和肺音的分离方法很多,典型的分离方法为非负矩阵分解方法,此方法对观测混合信号的幅度谱图进行分解,得到了组成心肺音的各个分量,然后使用无监督的聚类方法得到心音和肺音的频谱源信号,再用视频掩码技术恢复原始的心音和肺音信号,分离效果较好。
正常和异常呼吸音的声波特性已经有过大量的研究。权威观点认为,正常气管音是白噪声,典型频率100~500 Hz,在800 Hz时能量下降;正常肺音是低通滤波噪声,典型频率100~1 000 Hz,在200 Hz时能量下降;哮鸣音为正弦曲线,典型频率>100~5 000 Hz,一般持续时间>80 ms;细湿啰音为快速衰减波偏转,典型频率约650 Hz,一般持续时间约5 ms;粗湿啰音也为快速衰减波偏转,典型频率约350 Hz,一般持续时间约15 ms[18]。计算机通过抓取肺音特定信号特征,对肺音进行分析和分类。傅里叶变换是最常用的频谱分析算法,用于提供有关信号频率成分的信息。神经网络是一种用于特征识别和分类的机器学习算法,基于频率分解中选择的特征和相关的统计参数对不同的肺音进行分类[19]。通过机器的不断学习,不断完善算法,呼吸音判读的准确度、敏感度和特异度等指标也不断提升。几种常见肺音的波形见图1。
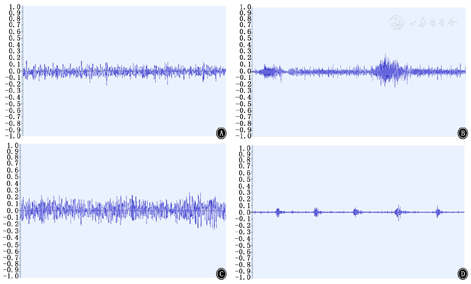
由于呼吸音需要人为定性,所以难免会存在一定的主观性。多位呼吸科医师的一致意见可以适当地减少主观因素的影响,但无法将主观性完全消除。Kahan等[22]的研究发现,3名以上的评估者通常不会带来多少增量效益。因此主观性不会因评估者的数量增加而有明显的减少,3位呼吸科医师参与定性即可。
儿童可听到的呼吸音与一般成年人听到的声音有不同的声学特征[23]。Gross等[24]指出,不同年龄组之间的肺音频谱成分有轻微的差异,尤其是婴儿和儿童。因此在对肺音进行机器学习时,儿童与成人的研究应分开探索,且成人与儿童的算法不能互用,否则AI判断的准确率将会下降。
Gurung等[25]的系统性综述显示,在肺音记录的方法、信号分析的计算机算法和结果分析的统计方法方面,目前各研究缺乏标准化。随着电子听诊和先进信号处理技术的出现,Andrès等[26]发起了一个合作项目——听诊器病理分析(analyse des sons auscultatoires pathologiques,ASAP,法国一个国家项目),旨在开发一个数据库,涵盖特定病理特征听诊声音的客观定义、肺音记录和存储的标准化格式,以促进卫生保健从业者之间的信息交流。此外,Sovijärvi等[27,28]已经开发了一套计算机呼吸音分析(CORSA)指南,以标准化计算机肺音分析中使用的定义和术语。ASAP和CORSA指南的进一步评估和推进,可能有助于标准化计算机肺音分析技术和定义,并促进其研究和开发。
过去,居家医疗只有体温计等简单辅助设备;现在,血压计、血糖仪、血氧仪等设备已实现民用化;未来,智能听诊器等更多的医疗设备将进入寻常百姓家。听诊作为呼吸科最常用、最简单、最低成本的检查手段,随着科技的发展,智能电子听诊器将逐步应用于家庭医疗场景,一定会被AI赋予新的时代特性,为人类健康事业贡献一份力量。
所有作者声明无利益冲突

























