
随着人工智能(AI)技术的兴起与发展,将AI应用于医疗健康领域正日益受到广泛关注。支气管哮喘(哮喘)是一种以慢性气道炎症和气道高反应性为特征的异质性疾病,其诊治依赖于各类临床数据。目前,AI在哮喘筛查诊断、管理监测、分类评估和治疗等多个方面得到广泛应用,为精准医学提供了新的方法。本文就上述研究进行综述,探讨AI在哮喘领域的应用进展,并为其精准治疗和预后评估提供新思路。


版权归中华医学会所有。
未经授权,不得转载、摘编本刊文章,不得使用本刊的版式设计。
除非特别声明,本刊刊出的所有文章不代表中华医学会和本刊编委会的观点。
人工智能(artificial intelligence,AI)是一项使用计算机化算法来剖析复杂数据的颠覆性技术。1956年,在达特矛斯会议上,以约翰麦卡锡为首的科学家们共同研究和探讨了用机器模拟智能的一系列问题,并首次提出"AI"这一术语,它标志着AI的正式诞生。支气管哮喘(哮喘)是一种由多种炎性细胞及其组分参与的异质性疾病,通常以慢性气道炎症为特征。主要症状是发作性的喘息、气促、胸闷和咳嗽,哮喘不仅对患者的生活质量造成影响,还给社会带来沉重的经济负担。近年来,随着AI技术的发展,哮喘领域的筛查诊断和管理监测方法正不断涌现,可协助医师识别不同表型的哮喘患者,加强个体和人群监测,评估疾病的恶化程度。本文将对近年来AI在哮喘中的应用进展进行阐述,以期对哮喘的分类评估和精准诊疗发挥指导和参考作用。
AI是应用科学和技术方法开发出能够模拟人类智能来解决问题的模型。机器学习属于AI的一个重要的分支学科,常被用来分析大量数据建立疾病模型[1]。机器学习疾病模型的建立通常包含3个步骤:数据的准备、模型的选择与训练和模型评估。机器学习技术可分为监督、半监督、非监督和强化学习[2,3]。监督学习是一种通过对已知输入和正确输出数据的训练来预测输出结果的算法,常被用在分类和回归问题上,包括逻辑回归(logistical regression,LR)、支持向量机(supportvector machine,SVM)、随机森林(random forest,RF)、极端梯度提升(extreme gradient boosting,XGBoost)、决策树(decision tree,DT)等,深度学习是监督学习的进一步升级,使用表征学习方法自动提取所需的特征,并对复杂的数据集进行分类,包括深度神经网络(deep neural network,DNN)、人工神经网络(artificial neural network,ANN);半监督学习在临床数据中的应用较少,其代表算法为K-最近邻分类算法(K-nearest neighbors,KNN);无监督学习是指从未知输出结果的输入数据中进行学习,从而识别输入数据的特征,并根据学习到的内容对其进行分类。聚类是无监督学习中最具有代表性的算法,K-均值聚类是其中之一;基于模型的聚类,又称为潜在类分析或混合建模;强化学习是一个基于奖励系统的决策过程,有助于智能体之间的交互建模,但在生物医学领域应用较少。自然语言处理(natural language processing,NLP)是将自然人类语言转化为结构化计算机语言的技术,也是AI的一个子领域,常以深度学习作为语言处理的基本算法;NLP最常见的使用方式是对电子健康记录进行临床转化研究[4,5,6];使用自然语言处理技术挖掘电子病历中的命名实体及其关系成为电子病历信息抽取领域的主要研究内容,也是推动电子病历在医疗健康服务中应用最重要的一部分。
随着AI在医学中的应用,NLP被广泛运用于哮喘的诊断,该方法可以处理文本信息并在个体水平对哮喘状态进行识别[7]。Wi等[8]在一项回顾性出生队列研究中用NLP方法提取电子病历信息,构建哮喘预测模型用于儿童哮喘诊断,并确定了过敏性鼻炎、湿疹、孕期母亲吸烟史、出生后吸烟史、无母乳喂养史和哮喘家族史等危险因素,该模型的敏感度、特异度、阳性及阴性预测值分别为97%、95%、90%和98%。预定哮喘标准(Predetermined Asthma Criteria,PAC)是专业医疗机构建议作为哮喘诊断的关键症状指标(表1),包括复发性喘息、夜间咳嗽、呼吸困难和气道高反应性等呼吸道症状;Wi等[9]进一步运用NLP技术对PAC文本信息进行处理,构建了能够在电子病历中识别哮喘状态的NLP-PAC算法,该算法包括两个步骤:第一个步骤是在文本中查找与PAC匹配的哮喘相关概念,第二个步骤是根据文本中的可用证据确定患者的哮喘状态;除了阳性预测值,该模型的各项评价指标均在90%以上;与人工浏览病历相比,NLP方法的诊断效率更高;此外,Kaur等[10]在患者电子健康记录中开发出类似的算法,该算法能预测哮喘预测指数(asthma prediction index,API)阳性的儿童哮喘,具体步骤和NLP-PAC算法相同;API是经研究者验证过的预测哮喘的标准,具体指的是:如果患者频繁喘息发作(即1年内2次或多次喘息发作)并且满足API中的一项或两项次要标准,则定义为哮喘的存在;在这项研究中,NLP-API算法对哮喘状态的确认与人工的结果一致,且这种一致性不受性别、种族及胎龄的影响;上述研究大部分集中在儿童哮喘领域;总之,NLP是一种根据患者的电子病历信息对哮喘进行识别的机器学习算法,可对文本信息进行二次利用,从而识别出电子病历中的有效信息,确定患者的疾病状态,得到一个较为客观的诊断。
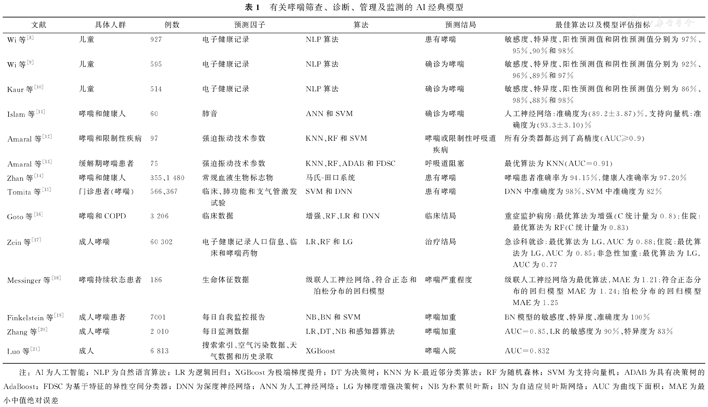
有关哮喘筛查、诊断、管理及监测的AI经典模型
有关哮喘筛查、诊断、管理及监测的AI经典模型
| 文献 | 具体人群 | 例数 | 预测因子 | 算法 | 预测结局 | 最佳算法以及模型评估指标 |
|---|---|---|---|---|---|---|
| Wi等[8] | 儿童 | 927 | 电子健康记录 | NLP算法 | 患有哮喘 | 敏感度、特异度、阳性预测值和阴性预测值分别为97%、95%、90%和98% |
| Wi等[9] | 儿童 | 595 | 电子健康记录 | NLP算法 | 确诊为哮喘 | 敏感度、特异度、阳性预测值和阴性预测值分别为92%、96%、89%和97% |
| Kaur等[10] | 儿童 | 514 | 电子健康记录 | NLP算法 | 确诊为哮喘 | 敏感度、特异度、阳性预测值和阴性预测值分别为86%、98%、88%和98% |
| Islam等[11] | 哮喘和健康人 | 60 | 肺音 | ANN和SVM | 确诊为哮喘 | 人工神经网络:准确度为(89.2±3.87)%,支持向量机:准确度为(93.3±3.10)% |
| Amaral等[12] | 哮喘和限制性疾病 | 97 | 强迫振动技术参数 | KNN、RF和SVM | 哮喘或限制性呼吸道疾病 | 所有分类器都达到了高精度(AUC≥0.9) |
| Amaral等[13] | 缓解期哮喘患者 | 75 | 强迫振动技术参数 | KNN、RF、ADAB和FDSC | 呼吸道阻塞 | 最优算法为KNN(AUC=0.91) |
| Zhan等[14] | 哮喘和健康人 | 355、1 480 | 常规血液生物标志物 | 马氏-田口系统 | 患有哮喘 | 哮喘患者准确率为94.15%,健康人准确率为97.20% |
| Tomita等[15] | 门诊患者(哮喘) | 566、367 | 临床、肺功能和支气管激发试验 | SVM和DNN | 患有哮喘 | DNN中准确度为98%,SVM中准确度为82% |
| Goto等[16] | 哮喘和COPD | 3 206 | 临床数据 | 增强、RF、LR和DNN | 临床结局 | 重症监护病房:最优算法为增强(C统计量为0.8);住院:最优算法为RF(C统计量为0.83) |
| Zein等[17] | 成人哮喘 | 60 302 | 电子健康记录人口信息、临床和哮喘药物 | LR、RF和LG | 治疗结局 | 急诊科就诊:最优算法为LG,AUC为0.88;住院:最优算法为LG,AUC为0.85;非急性加重:最优算法为LG,AUC为0.77 |
| Messinger等[18] | 哮喘持续状态患者 | 186 | 生命体征数据 | 级联人工神经网络、符合正态和泊松分布的回归模型 | 哮喘严重程度 | 级联人工神经网络为最优算法,MAE为1.21;符合正态分布的回归模型MAE为1.24;泊松分布的回归模型MAE为1.25 |
| Finkelstein等[19] | 成人哮喘患者 | 7001 | 每日自我监控报告 | NB、BN和SVM | 哮喘加重 | BN模型的敏感度、特异度、准确度为100% |
| Zhang等[20] | 成人哮喘 | 2 010 | 每日监测数据 | LR、DT、NB和感知器算法 | 哮喘加重 | AUC=0.85,LR的敏感度为90%、特异度为83% |
| Luo等[21] | 成人 | 6 813 | 搜索索引、空气污染数据、天气数据和历史录取 | XGBoost | 哮喘入院 | AUC=0.832 |
注:AI为人工智能;NLP为自然语言算法;LR为逻辑回归;XGBoost为极端梯度提升;DT为决策树;KNN为K-最近邻分类算法;RF为随机森林;SVM为支持向量机;ADAB为具有决策树的AdaBoost;FDSC为基于特征的异性空间分类器;DNN为深度神经网络;ANN为人工神经网络;LG为梯度增强决策树;NB为朴素贝叶斯;BN为自适应贝叶斯网络;AUC为曲线下面积;MAE为最小中值绝对误差
为了改善现有诊断技术的不足,研究者开始运用多种机器学习方法开发哮喘诊断的检测系统,以期找到能够改善现有诊断的新方法;Islam等[11]收集了60名受试者(30名正常和30例哮喘)后胸部4个不同位置的肺音,对其进行预处理、特征提取,并使用ANN和SVM对不同通道的肺音进行分类组合,实现了用多通道采集肺音来诊断哮喘。强制振荡技术(forced oscillation technique,FOT)是一种使用正弦系统识别技术评估呼吸力学的方法,能够改善肺功能诊断气道阻塞的侵入性;有望对哮喘的诊断起到辅助性作用;Amaral等[12,13]从75名志愿者(39名有阻塞,36名无阻塞)获取了FOT参数,运用4种监督学习技术来预测哮喘的气道阻塞,包括KNN、RF、DT以及基于特征的异性空间分类器(feature-based dissimilarity space classifier,FDSC),发现谐振频率是诊断哮喘气道阻塞的最佳FOT参数。在这项研究中,每一种分类模型的识别能力都实现了高精度,即AUC≥0.9,但该研究缺乏外部数据集验证结果。
除了电子病历信息和FOT数据,常见的哮喘临床指标也被研究者结合起来,作为机器学习的输入端数据。Zhan等[14]用健康个体和哮喘患者的血常规数据,构建出能智能诊断哮喘的MTS分类系统,该系统筛选出了7种能辅助哮喘诊断的血常规生物标志物:血小板分布宽度、平均血小板体积、白细胞计数、嗜酸粒细胞计数、淋巴细胞比值、淋巴细胞计数及红细胞平均血红蛋白浓度;MTS对哮喘患者的分类能力达到了94.15%,显著优于传统的SVM方法;Tomita等[15]研究显示,与传统的机器学习算法(如回归分析、SVM)相比,深度学习能够改善机器学习模型对哮喘患者的诊断效能。当基于症状体征、生化指标、肺功能测试和支气管激发试验诊断成人哮喘时,深度学习模型的准确率高(0.98),明显高于SVM(0.82)和回归分析(0.94)。
为了准确对哮喘患者的病情进行监测和提前干预,许多学者研究机器学习算法来辅助临床决策,预测疾病临床结局,为医师提供多角度的病症分析[22];Goto等[16]使用患者的分诊数据作为预测因子,例如:人口统计学、到达模式、生命体征、主诉及合并症,用于预测在急诊科就诊的哮喘患者的临床结局,结果表明,RF算法对"住院"的预测能力最强(C统计量0.83);Zein等[17]使用3种机器学习算法和60 302例哮喘患者的门诊数据建立起预测哮喘恶化的模型,发现LightGBM在预测哮喘相关的急诊就诊和住院治疗方面表现出更好的效能。Messinger等[18]收集儿科重症病房危重哮喘患儿的生命体征数据(心率、呼吸频率、血氧饱和度)作为输入数据,已经评定的儿童哮喘评分作为输出数据,运用人工神经网络算法创建了一种新型的儿科自动哮喘呼吸评分系统,用于评估急性哮喘发作的严重程度。
AI技术在开发慢性病远程监控系统方面有重要的潜力,可以从个体和人群水平上建立预测模型,用于哮喘的管理和监测[23,24]。Finkelstein和Jeong等[19]通过家庭远程管理系统收集了7 001例哮喘患者的电子日记,预先根据患者的症状和呼气流量峰值设定一个"急性发作"警报水平,使用朴素贝叶斯(naive Bayesian classifier,NB)、自适应贝叶斯网络(adaptive Bayesian network,BN)和SVM对被定义的急性发作进行预测,发现第8天是预测急性发作的最佳时间窗,此时模型的特异度和敏感度最大;Zhang等[20]基于2 010例哮喘患者的576个严重加重事件的每日监测数据,预测了患者住院、急诊治疗、口服激素的发生,最佳算法是logistic回归联合主成分分析,其敏感度达到90%以上。Luo等[21]将空气污染、气象和历史入院数据结合起来,以4种大气污染物(PM2.5、PM10、SO2和NO2)作为基本预测因子,运用XGBoost方法来预测哮喘入院人数,模型的曲线下面积是0.832,该研究弥补了单独使用互联网搜索数据进行疾病预测的不足;总之,机器学习算法能够预测哮喘加重及恶化的临床结局,从个体和人群水平对哮喘进行管理监测;
正确识别哮喘的类型是进行个性化治疗的关键。AI与机器学习的推广应用使得对哮喘表型的识别更加智能、方便[25,26]。聚类分析和潜在类分析能将研究对象分为相对同质的群组,是哮喘表型识别中使用最多的机器学习算法[27];Wu等[28]对346例成人哮喘患者的临床、生理、炎症指标和人口学变量进行多核聚类,将这些变量与服用激素后的痰数据相匹配,得出对吸入性糖皮质激素(inhabled corticosteroids,ICS)有不同反应的4组哮喘患者:第1组和第2组由患有过敏性哮喘、肺功能正常且对ICS有适度反应的年轻个体组成,通过对比ICS治疗后患者痰液中性粒细胞和巨噬细胞百分比将两者分开。第3组受试者为迟发性哮喘患者,其特点为:低肺功能、基线嗜酸粒细胞增多及最强的ICS反应性。第4组主要由年轻的肥胖女性组成,其特点为:严重的气流受限、低嗜酸粒细胞炎症以及最低的ICS反应性。此外,Nabi等[29]使用3种机器学习算法,包括集成分类、SVM和KNN[30],通过分析55例哮喘患者的喘息声将哮喘分为3个严重程度(轻度、中度和重度),发现集成分类的分类效能最高,其阳性预测值达90%;
随着精准医学的发展,基因型和表型之间的相互作用被进一步探讨,联合遗传、免疫、环境等因素对哮喘表型进行多因素识别成为必不可少的步骤[30,31,32],AI技术为精准医学的发展提供了新的技术方法,提高了数据分析的准确性[33]。例如:Krautenbacher等[30]运用高维多变量分析策略,将问卷、诊断、基因型、微阵列、RT-qPCR、流式细胞术和细胞因子数据结合起来,将健康儿童、轻度至中度过敏性哮喘和非过敏性哮喘患者类群分开,改进了儿童哮喘表型的分类。Hallmark等[34]首先用潜在类别分析在儿童哮喘中确认了4种喘息表型,分别为不频繁、短暂、迟发和持续性喘息,发现在非洲裔和欧洲裔美国儿童中染色体17q SNP(rs2305480)与后3种喘息表型之间均存在关联:基于以上研究,机器学习可通过对多类型的哮喘临床数据进行分析,从而辅助临床决策,对患者采取个性化的治疗策略。
综上,在哮喘研究中,AI技术在解决儿童哮喘异质性方面取得了很大的成效,揭示了临床实践中具有潜在不同转化影响的疾病表型。机器学习能够包含来自多个来源的多个数据,与传统统计方法相比,它具有更高的预测精度。
尽管AI和机器学习在哮喘中应用的研究有很多,但很少有报道将其应用于疾病的治疗;除了对哮喘治疗效果的研究之外[35,36],尚未有研究探讨AI/机器学习在具体治疗方面的作用;Qin等[37]采用深度学习算法对CT图像数据进行处理,评价小气道功能,并分析不同糖皮质激素给药方式对哮喘小气道梗阻患儿的临床疗效;Hosseini等[38]通过修改由人工神经网络系统开发的遗传算法来预测具有抗炎和抗氧化作用的藏红花治疗80例轻至中度过敏性哮喘患者的效果。Luo等[39]提出了一种合并症组合设计,构建了5种预测治疗成本的模型,通过重新组合不同成本的合并症来预测治疗成本,对减低治疗成本和管理合并症有很大帮助。但是,这一预测系统的性能需要更多过敏性或其他类型患者来证实。总之,AI在哮喘治疗方面的研究很少,有待于进一步探索。
AI技术在哮喘领域中的应用是一个越来越引人热议的话题。机器学习是AI的一部分,能从复杂的数据中找到一定的规律,建立相关疾病模型,为解决实际问题提供辅助工具。从本文可以看出,AI在识别哮喘的表型、预测哮喘急性加重以及诊断检测方面有较为广泛的应用,但是在治疗方面的运用较少,距离哮喘的临床应用,还有很长的路要走,目前仍面临的许多挑战包括:(1)黑匣子效应:AI模型虽然有着很高的准确性,但其内部工作机制很难让人理解,可解释性差,医师和患者只能得到计算的结果,却不知为何而来;(2)人文伦理:AI技术的使用涉及患者的隐私问题,在通过大量数据进行训练的同时,容易造成患者数据的泄露;且在短时间内不能解决医患之间的人际关怀问题;(3)各方利益的权衡:机器学习需要大量高质量的数据进行训练,但医院信息系统数据缺少统一的标准,且很多数据没有自动化,这对医疗行业的数据共享和数据联盟造成很大的困难;总之,基于大数据的AI技术在哮喘中的应用研究才刚起步,机遇与挑战并存,前景广阔。未来的AI技术在哮喘医学领域的发展需从临床的实际需求出发,以充分发挥AI在大数据分析和智能决策上的优势。
所有作者声明无利益冲突

























